Это не ваше воображение — у моделей ChatGPT теперь действительно чаще возникают галлюцинации
На прошлой неделе OpenAI опубликовала документ, в котором подробно описываются различные внутренние тесты и выводы о своих моделях o3 и o4-mini. Основными отличиями этих новых моделей от первых версий ChatGPT, которые мы увидели в 2023 году, являются их усовершенствованное мышление и мультимодальные возможности. o3 и o4-mini могут генерировать изображения, выполнять поиск в Интернете, автоматизировать задачи, запоминать старые разговоры и решать сложные задачи. Однако, похоже, что эти улучшения также привели к неожиданным побочным эффектам.
Что говорят тесты?
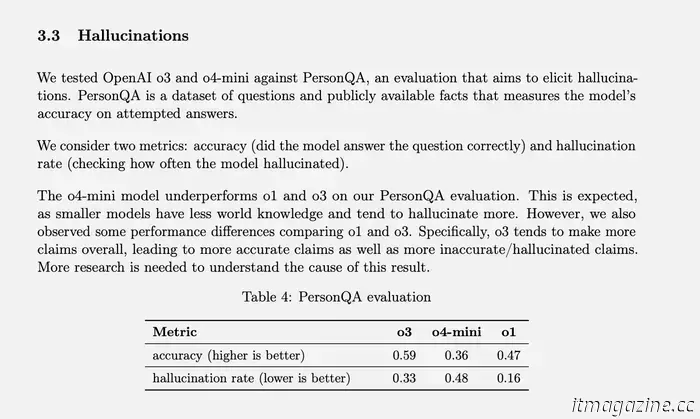
В OpenAI есть специальный тест для измерения частоты галлюцинаций, который называется PersonQA. Он включает в себя набор фактов о людях, у которых нужно “учиться”, и набор вопросов об этих людях, на которые нужно ответить. Точность модели измеряется на основе попыток ответить. Прошлогодняя модель o1 показала точность в 47% и частоту галлюцинаций в 16%.
Поскольку эти два значения не дают в сумме 100%, мы можем предположить, что остальные ответы не были ни точными, ни галлюцинациями. Модель может иногда говорить, что она не знает или не может найти нужную информацию, она может вообще не предъявлять никаких претензий и вместо этого предоставлять соответствующую информацию, или она может допустить небольшую ошибку, которую нельзя классифицировать как полноценную галлюцинацию.
OpenAI
Когда o3 и o4-mini были протестированы на соответствие этой оценке, они галлюцинировали значительно чаще, чем o1. Согласно OpenAI, это было в некоторой степени ожидаемо для модели o4-mini, поскольку она меньше по размеру и обладает меньшими знаниями о мире, что приводит к большему количеству галлюцинаций. Тем не менее, достигнутый показатель галлюцинаций в 48% кажется очень высоким, учитывая, что o4-mini - это коммерчески доступный продукт, который люди используют для поиска в Интернете и получения всевозможной информации и советов.
полноразмерная модель o3 во время теста вызывала галлюцинации в 33% случаев, что превосходит показатели o4-mini, но удваивает частоту галлюцинаций по сравнению с o1. Однако у него также был высокий показатель точности, что OpenAI объясняет своей тенденцией предъявлять больше требований в целом. Итак, если вы используете любую из этих двух новых моделей и заметили множество галлюцинаций, это не просто ваше воображение. (Может быть, мне стоит пошутить: “Не волнуйся, это не у тебя галлюцинации”.)
Что такое “галлюцинации” ИИ и почему они случаются?
Хотя вы, вероятно, уже слышали о том, что модели искусственного интеллекта “галлюцинируют”, не всегда понятно, что это значит. Всякий раз, когда вы используете продукт искусственного интеллекта, OpenAI или какой-либо другой, вы почти гарантированно увидите где-нибудь заявление об отказе от ответственности, в котором говорится, что его ответы могут быть неточными, и вы должны сами проверить факты.
Неточная информация может поступать отовсюду — иногда в Википедию попадает неприятный факт, или пользователи выкладывают бессмыслицу на Reddit, и эта дезинформация может найти отражение в ответах искусственного интеллекта. Например, обзоры Google с использованием искусственного интеллекта привлекли большое внимание, когда в нем был предложен рецепт пиццы, в состав которого входил “нетоксичный клей”. В конце концов, выяснилось, что Google почерпнул эту “информацию” из шутки в одной из тем Reddit.
Однако это не “галлюцинации”, это скорее прослеживаемые ошибки, которые возникают из-за неверных данных и неправильной интерпретации. Галлюцинации, с другой стороны, - это когда модель искусственного интеллекта выдвигает претензии без какого-либо четкого источника или причины. Такое часто случается, когда ИИ-модель не может найти информацию, необходимую для ответа на конкретный запрос, и OpenAI определил это как “склонность изобретать факты в моменты неопределенности”. Другие представители отрасли назвали это “творческим заполнением пробелов”.
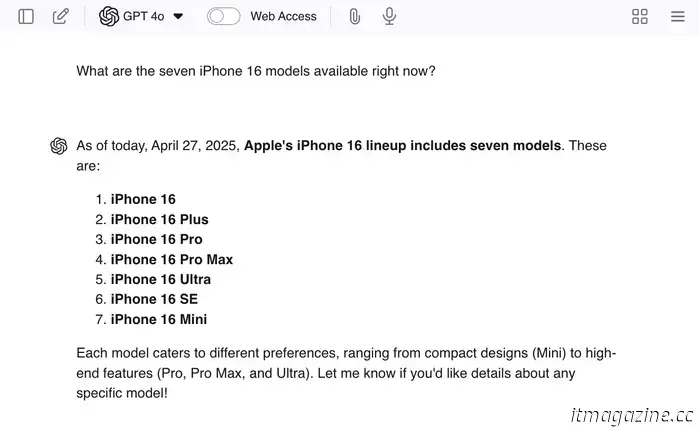
Вы можете спровоцировать галлюцинации, задавая в чате наводящие вопросы, например: “Какие семь моделей iPhone 16 доступны сейчас?” Поскольку семи моделей нет, магистр права, скорее всего, даст вам реальные ответы, а затем придумает дополнительные модели для завершения работы.
Я решила использовать свой пример в GPT 4o на всякий случай, на случай, если он действительно понравится, — и это действительно так! Уиллоу Робертс / Digital Trends
Чат-ботов, таких как ChatGPT, обучают не только работе с интернет-данными, которые определяют содержание их ответов, но и тому, “как отвечать”. Им показывают тысячи примеров запросов и подбирают идеальные ответы, чтобы поддержать правильный тон, отношение и уровень вежливости.
Эта часть учебного процесса - то, что заставляет магистра права говорить так, будто он согласен с вами или понимает то, что вы говорите, даже если остальная часть его результатов полностью противоречит этим утверждениям. Возможно, что эта тренировка может быть одной из причин того, что галлюцинации так часты, — потому что уверенный ответ на вопрос подкрепляется как более благоприятный исход по сравнению с ответом, который не отвечает на вопрос.
Нам кажется очевидным, что бессистемная ложь хуже, чем просто незнание ответа, но магистры не “врут”. Они даже не знают, что такое ложь. Некоторые люди говорят, что ошибки ИИ похожи на ошибки человека, и поскольку “мы не всегда делаем все правильно, то и от ИИ не стоит ожидать того же”. Однако важно помнить, что ошибки ИИ - это просто результат несовершенных процессов, разработанных нами.
Модели искусственного интеллекта не лгут, не создают недоразумений и не запоминают информацию неправильно, как это делаем мы. У них даже нет понятий точности или неточности — они просто предсказывают следующее слово в предложении на основе вероятностей. И поскольку, к счастью, мы все еще находимся в состоянии, когда наиболее часто произносимые слова, скорее всего, являются правильными, эти реконструкции часто отражают точную информацию. Это создает впечатление, что когда мы получаем “правильный ответ”, это просто случайный побочный эффект, а не результат, который мы спроектировали, — и это действительно так, как все работает.
Мы загружаем в эти модели всю информацию, имеющуюся в Интернете, но не сообщаем им, какая информация хорошая, а какая плохая, точная или неточная — мы вообще ничего им не сообщаем. У них нет базовых знаний или набора основополагающих принципов, которые помогли бы им самостоятельно разобраться в информации. Это всего лишь игра с числами — сочетания слов, которые наиболее часто встречаются в данном контексте, становятся “истиной” LLM. Для меня это звучит как система, которой суждено потерпеть крах и сгореть, но другие считают, что именно эта система приведет к созданию AGI (хотя это отдельная тема для обсуждения).
Что можно исправить?
OpenAI
Проблема в том, что OpenAI пока не знает, почему у этих продвинутых моделей чаще возникают галлюцинации. Возможно, проведя дополнительные исследования, мы сможем понять и устранить проблему, но есть вероятность, что все пойдет не так гладко. Компания, несомненно, продолжит выпускать все более и более “продвинутые” модели, и есть вероятность, что количество галлюцинаций будет расти.
В этом случае OpenAI, возможно, потребуется найти краткосрочное решение, а также продолжить исследование первопричины. В конце концов, эти модели - продукты, приносящие доход, и они должны быть в пригодном для использования состоянии. Я не специалист в области искусственного интеллекта, но, полагаю, моей первой идеей было бы создать какой—то совокупный продукт - интерфейс чата, который имеет доступ к нескольким различным моделям OpenAI.
Когда запрос требует расширенного анализа, он будет использовать GPT-4o, а когда он хочет свести к минимуму вероятность галлюцинаций, он будет использовать более старую модель, такую как o1. Возможно, компания смогла бы пойти еще дальше и использовать разные модели для обработки различных элементов одного запроса, а затем использовать дополнительную модель, чтобы в конце объединить все это воедино. Поскольку, по сути, это будет совместная работа нескольких моделей искусственного интеллекта, возможно, можно было бы также внедрить какую-то систему проверки фактов.
Однако повышение точности не является главной целью. Главная цель - снизить частоту галлюцинаций, а это значит, что мы должны ценить ответы, в которых говорится “я не знаю”, а также ответы с правильными ответами.
На самом деле, я понятия не имею, что предпримет OpenAI и насколько сильно его исследователи обеспокоены растущим числом галлюцинаций. Все, что я знаю, это то, что увеличение количества галлюцинаций вредно для конечных пользователей — это просто означает, что у нас появляется все больше и больше возможностей быть введенными в заблуждение, сами того не осознавая. Если вы увлекаетесь LLM, нет необходимости отказываться от их использования, но не позволяйте желанию сэкономить время возобладать над необходимостью проверять результаты. Всегда проверяйте факты!
Другие статьи
 Если Clair Obscur: Expedition 33 - лучшая игра всех времен, то именно поэтому
Клэр Обскур: "Экспедиция 33" выделяется тем, что нарушает правила всеми возможными способами.
Если Clair Obscur: Expedition 33 - лучшая игра всех времен, то именно поэтому
Клэр Обскур: "Экспедиция 33" выделяется тем, что нарушает правила всеми возможными способами.
 Я потратил 3000 долларов на ПК только для того, чтобы поиграть в игру стоимостью 20 долларов. Я ни о чем не жалею
Я энтузиаст создания ПК, но даже при всем моем опыте и знаниях я все равно стал жертвой того, что потратил "чуть больше". На самом деле мне это было не нужно.
Я потратил 3000 долларов на ПК только для того, чтобы поиграть в игру стоимостью 20 долларов. Я ни о чем не жалею
Я энтузиаст создания ПК, но даже при всем моем опыте и знаниях я все равно стал жертвой того, что потратил "чуть больше". На самом деле мне это было не нужно.
 10 лучших фильмов с рейтингом R, которые транслируются прямо сейчас
От "Аноры", удостоенной премии "Оскар", до современного классического "Паразита" - вот 10 лучших фильмов с рейтингом R, которые транслируются прямо сейчас.
10 лучших фильмов с рейтингом R, которые транслируются прямо сейчас
От "Аноры", удостоенной премии "Оскар", до современного классического "Паразита" - вот 10 лучших фильмов с рейтингом R, которые транслируются прямо сейчас.
 Китайская компания Momenta рекламирует услуги ассистента при вождении с Toyota, GM и другими компаниями, ориентируясь на глобальную экспансию
По состоянию на прошлый год Momenta установила свои функции ADAS на 26 моделях и ожидает, что к концу мая на дорогах будет 300 000 автомобилей, использующих эту технологию.
Китайская компания Momenta рекламирует услуги ассистента при вождении с Toyota, GM и другими компаниями, ориентируясь на глобальную экспансию
По состоянию на прошлый год Momenta установила свои функции ADAS на 26 моделях и ожидает, что к концу мая на дорогах будет 300 000 автомобилей, использующих эту технологию.
 Отключение термостата Nest от Google - это предупреждение для всех пользователей "умного дома"
Компания Google объявила об обновлении своих термостатов Nest Learning первого и второго поколения, срок службы которых истек.
Отключение термостата Nest от Google - это предупреждение для всех пользователей "умного дома"
Компания Google объявила об обновлении своих термостатов Nest Learning первого и второго поколения, срок службы которых истек.
Это не ваше воображение — у моделей ChatGPT теперь действительно чаще возникают галлюцинации
Согласно внутренним тестам, новые модели, такие как o3 и o4-mini, вызывают значительно больше галлюцинаций, чем старые версии, и OpenAI не знает почему.