No es tu imaginación: los modelos de ChatGPT realmente alucinan más ahora
OpenAI publicó un artículo la semana pasada que detalla varias pruebas internas y hallazgos sobre sus modelos o3 y o4-mini. Las principales diferencias entre estos modelos más nuevos y las primeras versiones de ChatGPT que vimos en 2023 son su razonamiento avanzado y sus capacidades multimodales. o3 y o4-mini pueden generar imágenes, buscar en la web, automatizar tareas, recordar conversaciones antiguas y resolver problemas complejos. Sin embargo, parece que estas mejoras también han traído efectos secundarios inesperados.
¿Qué dicen las pruebas?
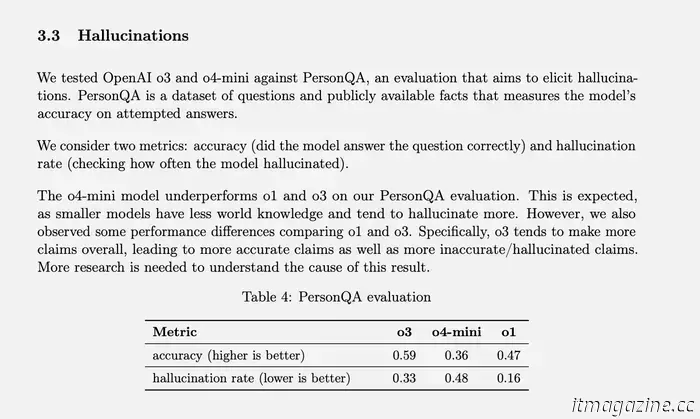
OpenAI tiene una prueba específica para medir las tasas de alucinaciones llamada PersonQA. Incluye un conjunto de datos sobre las personas de las que "aprender" y un conjunto de preguntas sobre esas personas a las que responder. La precisión del modelo se mide en función de sus intentos de responder. El modelo o1 del año pasado logró una tasa de precisión del 47% y una tasa de alucinaciones del 16%.
Dado que estos dos valores no suman el 100%, podemos suponer que el resto de las respuestas no fueron precisas ni alucinaciones. El modelo a veces puede decir que no sabe o que no puede localizar la información, es posible que no haga ningún reclamo y proporcione información relacionada en su lugar, o puede cometer un pequeño error que no puede clasificarse como una alucinación total.
OpenAI
Cuando se probaron o3 y o4-mini contra esta evaluación, alucinaron a una tasa significativamente mayor que o1. Según OpenAI, esto era algo esperado para el modelo o4-mini porque es más pequeño y tiene menos conocimiento del mundo, lo que lleva a más alucinaciones. Aún así, la tasa de alucinaciones del 48% que logró parece muy alta considerando que o4-mini es un producto disponible comercialmente que la gente está usando para buscar en la web y obtener todo tipo de información y consejos diferentes.
o3, el modelo de tamaño completo, alucinó en el 33% de sus respuestas durante la prueba, superando a o4-mini pero duplicando la tasa de alucinaciones en comparación con o1. Sin embargo, también tuvo una alta tasa de precisión, que OpenAI atribuye a su tendencia a hacer más afirmaciones en general. Entonces, si usa cualquiera de estos dos modelos más nuevos y ha notado muchas alucinaciones, no es solo su imaginación. (Tal vez debería hacer una broma allí como "No te preocupes, no eres tú quien está alucinando.”)
¿Qué son las "alucinaciones" de IA y por qué ocurren?
Si bien es probable que hayas oído hablar de modelos de IA que "alucinan" antes, no siempre está claro qué significa. Siempre que use un producto de IA, OpenAI o de otro tipo, tiene la garantía de ver un descargo de responsabilidad en alguna parte que diga que sus respuestas pueden ser inexactas y que debe verificar los hechos por sí mismo.
La información inexacta puede provenir de todas partes; a veces, un mal hecho llega a Wikipedia o los usuarios escupen tonterías en Reddit, y esta información errónea puede llegar a las respuestas de IA. Por ejemplo, las descripciones generales de IA de Google llamaron mucho la atención cuando sugirió una receta de pizza que incluía "pegamento no tóxico. Al final, se descubrió que Google obtuvo esta "información" de una broma en un hilo de Reddit .
Sin embargo, estas no son "alucinaciones", son más como errores rastreables que surgen de datos incorrectos y malas interpretaciones. Las alucinaciones, por otro lado, son cuando el modelo de IA hace un reclamo sin una fuente o razón clara. A menudo sucede cuando un modelo de IA no puede encontrar la información que necesita para responder a una consulta específica, y OpenAI lo ha definido como "una tendencia a inventar hechos en momentos de incertidumbre."Otras figuras de la industria lo han llamado "llenar vacíos creativos.”
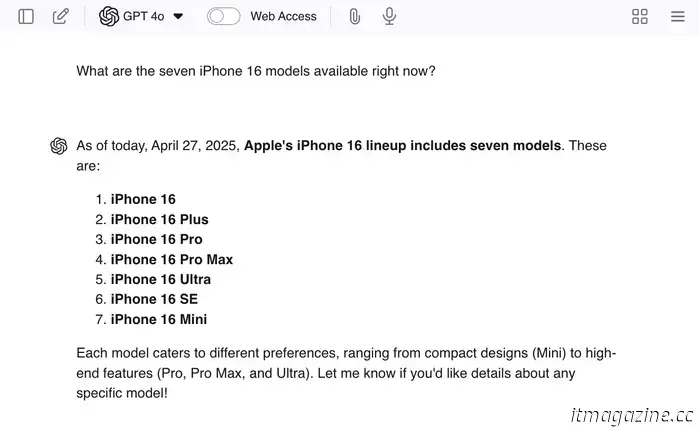
Puede alentar las alucinaciones haciendo preguntas destacadas de ChatGPT como " ¿Cuáles son los siete modelos de iPhone 16 disponibles en este momento ?"Dado que no hay siete modelos, es probable que el LLM le brinde algunas respuestas reales y luego invente modelos adicionales para terminar el trabajo .
Decidí incorporar mi ejemplo a GPT 4o por si realmente se enamoraba de él, ¡y así fue! Willow Roberts / Tendencias digitales
Los chatbots como ChatGPT no solo están capacitados en los datos de Internet que informan el contenido de sus respuestas, sino que también están capacitados en "cómo responder". Se les muestran miles de consultas de ejemplo y respuestas ideales coincidentes para fomentar el tipo correcto de tono, actitud y nivel de cortesía.
Esta parte del proceso de capacitación es lo que hace que un LLM parezca que está de acuerdo con usted o entiende lo que está diciendo, incluso cuando el resto de su resultado contradice completamente esas afirmaciones. Es posible que este entrenamiento sea parte de la razón por la que las alucinaciones son tan frecuentes, porque una respuesta segura que responde a la pregunta se ha reforzado como un resultado más favorable en comparación con una respuesta que no responde a la pregunta.
Para nosotros, parece obvio que decir mentiras al azar es peor que simplemente no saber la respuesta, pero los LLM no " mienten."Ni siquiera saben qué es una mentira. Algunas personas dicen que los errores de la IA son como errores humanos, y dado que "no hacemos las cosas bien todo el tiempo, tampoco deberíamos esperar que la IA lo haga."Sin embargo, es importante recordar que los errores de la IA son simplemente el resultado de procesos imperfectos diseñados por nosotros.
Los modelos de IA no mienten, desarrollan malentendidos ni recuerdan mal la información como lo hacemos nosotros. Ni siquiera tienen conceptos de precisión o inexactitud; simplemente predicen la siguiente palabra en una oración en función de las probabilidades. Y dado que afortunadamente todavía estamos en un estado en el que es probable que lo que se dice con más frecuencia sea lo correcto, esas reconstrucciones a menudo reflejan información precisa. Eso hace que parezca que cuando obtenemos "la respuesta correcta", es solo un efecto secundario aleatorio en lugar de un resultado que hemos diseñado — y así es como funcionan las cosas.
Alimentamos a estos modelos con toda la información de Internet, pero no les decimos qué información es buena o mala, precisa o inexacta, no les decimos nada. Tampoco tienen conocimientos fundamentales existentes o un conjunto de principios subyacentes que les ayuden a clasificar la información por sí mismos. Todo es solo un juego de números: los patrones de palabras que existen con mayor frecuencia en un contexto dado se convierten en la "verdad" del LLM."Para mí, esto suena como un sistema que está destinado a fallar y arder, pero otros creen que este es el sistema que conducirá a la AGI (aunque esa es una discusión diferente.)
¿Cuál es la solución?
OpenAI
El problema es que OpenAI aún no sabe por qué estos modelos avanzados tienden a alucinar con más frecuencia. Quizás con un poco más de investigación, podamos comprender y solucionar el problema — pero también existe la posibilidad de que las cosas no salgan tan bien. Sin duda, la compañía seguirá lanzando más y más modelos "avanzados", y existe la posibilidad de que las tasas de alucinaciones sigan aumentando.
En este caso, OpenAI podría necesitar buscar una solución a corto plazo, así como continuar su investigación sobre la causa raíz. Después de todo, estos modelos son productos que generan dinero y deben estar en un estado utilizable. No soy científico de IA, pero supongo que mi primera idea sería crear algún tipo de producto agregado: una interfaz de chat que tenga acceso a múltiples modelos OpenAI diferentes.
Cuando una consulta requiere un razonamiento avanzado, recurriría a GPT-4o, y cuando desea minimizar las posibilidades de alucinaciones, recurriría a un modelo más antiguo como o1. Quizás la empresa podría volverse aún más elegante y usar diferentes modelos para encargarse de diferentes elementos de una sola consulta, y luego usar un modelo adicional para unirlo todo al final. Dado que esto sería esencialmente un trabajo en equipo entre múltiples modelos de IA, quizás también se podría implementar algún tipo de sistema de verificación de hechos.
Sin embargo, aumentar las tasas de precisión no es el objetivo principal. El objetivo principal es reducir las tasas de alucinaciones, lo que significa que debemos valorar las respuestas que dicen "no lo sé", así como las respuestas con las respuestas correctas.
En realidad, no tengo idea de qué hará OpenAI o cuán preocupados están realmente sus investigadores por la creciente tasa de alucinaciones. Todo lo que sé es que más alucinaciones son malas para los usuarios finales, solo significa más y más oportunidades para que nos engañen sin darnos cuenta. Si le gustan mucho los LLM, no hay necesidad de dejar de usarlos, pero no deje que el deseo de ahorrar tiempo supere la necesidad de verificar los resultados. ¡Siempre verifique los hechos!
Otros artículos
 Rival de Waymo en China Pony.ai reduce drásticamente el costo de la pila de autoconducción en un 70%
Pony.ai los robotaxis de última generación cuestan entre un 20% y un 30% menos que los de la unidad autónoma Waymo de su rival estadounidense Alphabet, dijo el CEO James Peng.
Rival de Waymo en China Pony.ai reduce drásticamente el costo de la pila de autoconducción en un 70%
Pony.ai los robotaxis de última generación cuestan entre un 20% y un 30% menos que los de la unidad autónoma Waymo de su rival estadounidense Alphabet, dijo el CEO James Peng.
 Usé una aplicación gratuita para solucionar mi mayor problema con macOS
Apple no ha incorporado un portapapeles a nivel de sistema en macOS. Maccy llena ese vacío maravillosamente, sin dejar de ser de código abierto y totalmente gratuito, si así lo desea.
Usé una aplicación gratuita para solucionar mi mayor problema con macOS
Apple no ha incorporado un portapapeles a nivel de sistema en macOS. Maccy llena ese vacío maravillosamente, sin dejar de ser de código abierto y totalmente gratuito, si así lo desea.
 las 10 mejores películas con clasificación R que se transmiten en este momento
Desde la ganadora del Oscar Anora hasta el clásico moderno Parasite, estas son las 10 mejores películas con clasificación R que se transmiten en este momento.
las 10 mejores películas con clasificación R que se transmiten en este momento
Desde la ganadora del Oscar Anora hasta el clásico moderno Parasite, estas son las 10 mejores películas con clasificación R que se transmiten en este momento.
 Preguntaste: Nintendo Switch 2, Los Mejores Teléfonos Android y Actualizaciones OLED
En el episodio de hoy de You Asked, analizamos algunas de sus preguntas tecnológicas candentes, incluidas las últimas sobre Nintendo Switch 2, los teléfonos Android recomendados y si vale la pena actualizar su televisor OLED para obtener un mejor revestimiento antirreflectante.
Preguntaste: Nintendo Switch 2, Los Mejores Teléfonos Android y Actualizaciones OLED
En el episodio de hoy de You Asked, analizamos algunas de sus preguntas tecnológicas candentes, incluidas las últimas sobre Nintendo Switch 2, los teléfonos Android recomendados y si vale la pena actualizar su televisor OLED para obtener un mejor revestimiento antirreflectante.
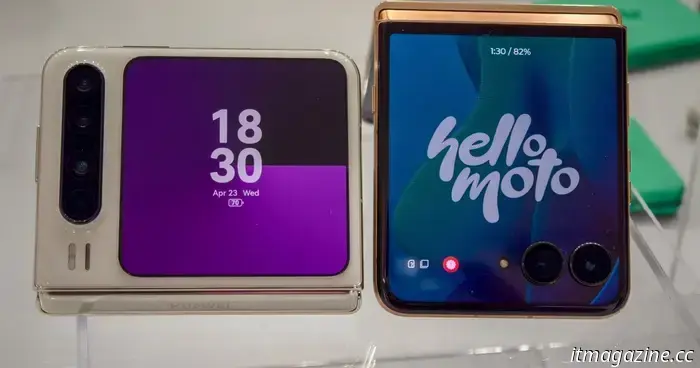 La respuesta de Huawei al Moto Razr Ultra 2025 me hace preguntarme quién tiene razón
¿Deberían los teléfonos plegables ser un teléfono inteligente más pequeño o una tableta más pequeña? Pasé tiempo con Huawei Pura X y Razr Ultra 2025 para responder exactamente a esta pregunta
La respuesta de Huawei al Moto Razr Ultra 2025 me hace preguntarme quién tiene razón
¿Deberían los teléfonos plegables ser un teléfono inteligente más pequeño o una tableta más pequeña? Pasé tiempo con Huawei Pura X y Razr Ultra 2025 para responder exactamente a esta pregunta
No es tu imaginación: los modelos de ChatGPT realmente alucinan más ahora
Según pruebas internas, los modelos más nuevos como o3 y o4-mini alucinan significativamente más que las versiones anteriores, y OpenAI no sabe por qué.