Google's TurboQuant reduces AI memory usage by six times, causing a stir in chip stock markets.
On Tuesday, Google released a research blog post detailing a new compression algorithm designed for AI models. Shortly thereafter, stocks in the memory sector began to decline. Micron fell by 3 percent, Western Digital dropped 4.7 percent, and SanDisk decreased by 5.7 percent as investors reassessed the actual physical memory requirements of the AI industry.
Named TurboQuant, the algorithm tackles a significant cost issue associated with operating large language models: the key-value cache. This high-speed data storage holds contextual information, preventing the need for the model to recompute it with each new token generation. As models process increasingly lengthy inputs, the cache expands significantly, utilizing GPU memory that could otherwise accommodate more users or larger models. TurboQuant compresses the cache to just 3 bits per value, down from the typical 16 bits, achieving a memory footprint reduction of at least six times, with no significant accuracy loss as per Google's benchmarks.
The research paper, set to be presented at ICLR 2026, was authored by Amir Zandieh, a research scientist at Google, and Vahab Mirrokni, a vice president and Google Fellow, along with associates from Google DeepMind, KAIST, and New York University. It builds upon two previous papers from the same team: QJL, presented at AAAI 2025, and PolarQuant, scheduled for AISTATS 2026.
TurboQuant's primary innovation lies in eliminating the overhead that often hampers the effectiveness of most compression techniques. Conventional quantization methods condense data vector sizes but require additional constants for accurate decompression. These constants usually contribute one or two extra bits per number, thereby diminishing the overall compression.
TurboQuant circumvents this issue through a two-step process. The first step, known as PolarQuant, transforms data vectors from standard Cartesian coordinates into polar coordinates, breaking each vector into magnitude and angle components. Due to the predictable, concentrated patterns of angular distributions, the system entirely bypasses the costly per-block normalization step. In the second stage, QJL, based on the Johnson-Lindenstrauss transform, further reduces the minimal residual error from the first stage to a single sign bit per dimension. The end result is a representation that maximizes the use of its compression capacity to capture the original data’s meaning while minimizing the budget allocated to error correction, without wasting any on normalization constants.
Google evaluated TurboQuant across five standard benchmarks for long-context language models, including LongBench, Needle in a Haystack, and ZeroSCROLLS, utilizing open-source models from the Gemma, Mistral, and Llama families. At 3 bits, TurboQuant either matched or exceeded the performance of KIVI, the current benchmark for key-value cache quantization, published at ICML 2024. In needle-in-a-haystack retrieval tasks, where the goal is to find a specific piece of information within a lengthy text, TurboQuant achieved perfect scores while compressing the cache sixfold. At 4-bit precision, the algorithm provided up to an eight-fold speed increase in attention computation on Nvidia H100 GPUs compared to the uncompressed 32-bit baseline.
The market's response was quick and, according to several analysts, disproportionate. Wells Fargo analyst Andrew Rocha commented that TurboQuant directly challenges the cost curve associated with memory in AI systems. If it gains widespread adoption, it raises concerns about the actual memory capacity needed in the industry. However, Rocha and others warned that demand for AI memory remains robust, and compression algorithms have been around for years without fundamentally changing procurement volumes.
That said, concerns aren't unwarranted. AI infrastructure spending is surging, with Meta alone pledging up to $27 billion in a recent agreement with Nebius for dedicated compute resources, while Google, Microsoft, and Amazon are together planning to invest hundreds of billions in capital expenditures on data centers through 2026. A technology cutting memory requirements by six times does not equate to a six-fold decrease in spending, as memory is only one part of a data center's expenses. However, it does alter the cost structure, and in an industry operating at this scale, even slight efficiency improvements can have significant impacts.
TurboQuant emerges at a time when the AI sector is being compelled to evaluate the costs associated with inference. Training a model incurs a one-time cost, no matter how large; however, operating it and managing millions of queries daily with acceptable speed and accuracy is the ongoing expense that dictates whether AI products are financially viable on a larger scale. The key-value cache plays a crucial role in this assessment: it represents the bottleneck determining how many concurrent users a single GPU can cater to and the feasible length of context windows a model can effectively manage.
Techniques like TurboQuant are part of a broader initiative aimed at reducing inference costs, alongside advancements in hardware such as Nvidia’s Vera Rubin architecture and Google’s own Ironwood TPUs. The key question remains whether these efficiency gains will lead to a
Other articles
 Enhance Your Home Gym with RITFIT’s Discounts This March
Strength training no longer requires a trip to the gym. RitFit's March sale on versatile workout equipment allows you to create your home gym. Whether for your personal use or as a gift for fellow fitness lovers, the M2 Smith Package is transforming workouts with its convenience.
Enhance Your Home Gym with RITFIT’s Discounts This March
Strength training no longer requires a trip to the gym. RitFit's March sale on versatile workout equipment allows you to create your home gym. Whether for your personal use or as a gift for fellow fitness lovers, the M2 Smith Package is transforming workouts with its convenience.
 This might be our first glimpse of Samsung's forthcoming Galaxy Z Fold 8 Wide.
Leaked CAD images of the Galaxy Z Fold 8 Wide show a foldable device that is wider and shorter, designed by Samsung to compete directly with Apple's inaugural foldable iPhone.
This might be our first glimpse of Samsung's forthcoming Galaxy Z Fold 8 Wide.
Leaked CAD images of the Galaxy Z Fold 8 Wide show a foldable device that is wider and shorter, designed by Samsung to compete directly with Apple's inaugural foldable iPhone.
 Samsung has introduced the Galaxy A57 and A37, featuring updated processors and enhanced cameras.
Samsung has officially unveiled the Galaxy A57 and A37, featuring new Exynos processors, enhanced night photography capabilities, and the well-known essentials of a mid-range device.
Samsung has introduced the Galaxy A57 and A37, featuring updated processors and enhanced cameras.
Samsung has officially unveiled the Galaxy A57 and A37, featuring new Exynos processors, enhanced night photography capabilities, and the well-known essentials of a mid-range device.
 Meta and YouTube were held responsible in a groundbreaking trial concerning social media addiction.
A jury in Los Angeles determined that Meta and YouTube purposefully created addictive platforms that caused harm to a young user, marking the first verdict among 1,500 ongoing cases.
Meta and YouTube were held responsible in a groundbreaking trial concerning social media addiction.
A jury in Los Angeles determined that Meta and YouTube purposefully created addictive platforms that caused harm to a young user, marking the first verdict among 1,500 ongoing cases.
 Intel's latest Arc Pro B70 and B65 GPUs are designed for artificial intelligence tasks.
Intel has introduced the Arc Pro B70 and B65 GPUs, tailored for AI inference and professional applications, which come with up to 32 GB of GDDR6 memory and complete PCIe 5.0 compatibility.
Intel's latest Arc Pro B70 and B65 GPUs are designed for artificial intelligence tasks.
Intel has introduced the Arc Pro B70 and B65 GPUs, tailored for AI inference and professional applications, which come with up to 32 GB of GDDR6 memory and complete PCIe 5.0 compatibility.
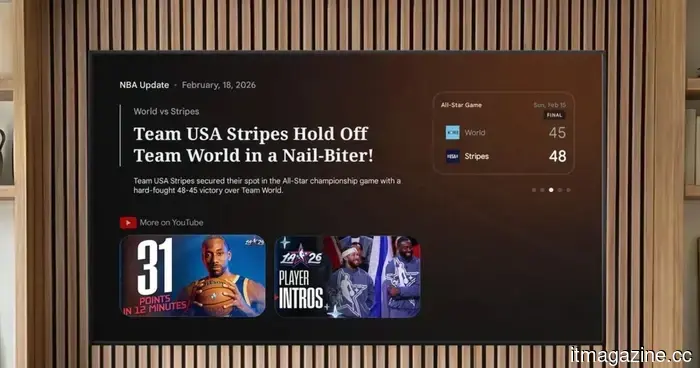 Gemini on Google TV can now provide answers to your questions, explain concepts, and offer sports updates.
Google is introducing Gemini functionalities to Google TV, allowing users to ask questions, delve into subjects, and keep up with sports updates, all in a single location.
Gemini on Google TV can now provide answers to your questions, explain concepts, and offer sports updates.
Google is introducing Gemini functionalities to Google TV, allowing users to ask questions, delve into subjects, and keep up with sports updates, all in a single location.
Google's TurboQuant reduces AI memory usage by six times, causing a stir in chip stock markets.
Google's TurboQuant algorithm reduces LLM key-value caches to 3 bits without any loss of accuracy. Following the announcement, memory stocks dropped within hours.