El TurboQuant de Google comprime la memoria de IA en 6x, sacude las acciones de chips.
Google publicó un artículo en su blog de investigación el martes sobre un nuevo algoritmo de compresión para modelos de IA. En cuestión de horas, las acciones de memoria comenzaron a caer. Micron bajó un 3 por ciento, Western Digital perdió un 4.7 por ciento y SanDisk cayó un 5.7 por ciento, mientras los inversores recalculaban cuánta memoria física podría necesitar realmente la industria de la IA.
El algoritmo se llama TurboQuant y aborda uno de los cuellos de botella más costosos en la ejecución de grandes modelos de lenguaje: la caché de clave-valor, un almacén de datos de alta velocidad que mantiene información de contexto para que el modelo no tenga que recomputarla con cada nuevo token que genera. A medida que los modelos procesan entradas más largas, la caché crece rápidamente, consumiendo memoria de GPU que de otro modo podría usarse para atender a más usuarios o ejecutar modelos más grandes. TurboQuant comprime la caché a solo 3 bits por valor, bajando de los 16 estándar, reduciendo su huella de memoria al menos seis veces sin, según los benchmarks de Google, ninguna pérdida medible en precisión.
El artículo, que se presentará en ICLR 2026, fue escrito por Amir Zandieh, un científico investigador en Google, y Vahab Mirrokni, un vicepresidente y Google Fellow, junto con colaboradores de Google DeepMind, KAIST y la Universidad de Nueva York. Se basa en dos artículos anteriores del mismo grupo: QJL, publicado en AAAI 2025, y PolarQuant, que aparecerá en AISTATS 2026.
Cómo funciona
La innovación central de TurboQuant es eliminar el sobrecoste que hace que la mayoría de las técnicas de compresión sean menos efectivas de lo que sus cifras principales sugieren. Los métodos de cuantización tradicionales reducen el tamaño de los vectores de datos, pero deben almacenar constantes adicionales, valores de normalización que el sistema necesita para descomprimir los datos con precisión. Estas constantes suelen añadir uno o dos bits extra por número, deshaciendo parcialmente la compresión.
El 💜 de la tecnología de la UE
Los últimos rumores de la escena tecnológica de la UE, una historia de nuestro sabio fundador Boris y un arte de IA cuestionable. Es gratis, cada semana, en tu bandeja de entrada. ¡Suscríbete ahora!
TurboQuant evita esto a través de un proceso de dos etapas. La primera etapa, llamada PolarQuant, convierte vectores de datos de coordenadas cartesianas estándar a coordenadas polares, separando cada vector en una magnitud y un conjunto de ángulos. Debido a que las distribuciones angulares siguen patrones predecibles y concentrados, el sistema puede omitir completamente el costoso paso de normalización por bloque. La segunda etapa aplica QJL, una técnica basada en la transformación de Johnson-Lindenstrauss, que reduce el pequeño error residual de la primera etapa a un solo bit de signo por dimensión. El resultado combinado es una representación que utiliza la mayor parte de su presupuesto de compresión para capturar el significado de los datos originales y un presupuesto residual mínimo para la corrección de errores, sin desperdiciar sobrecostes en constantes de normalización.
Google probó TurboQuant en cinco benchmarks estándar para modelos de lenguaje de largo contexto, incluyendo LongBench, Needle in a Haystack y ZeroSCROLLS, utilizando modelos de código abierto de las familias Gemma, Mistral y Llama. A 3 bits, TurboQuant igualó o superó a KIVI, la línea base estándar actual para la cuantización de caché de clave-valor, que fue publicada en ICML 2024. En tareas de recuperación de needle-in-a-haystack, que prueban si un modelo puede localizar una única pieza de información enterrada en un largo pasaje, TurboQuant logró puntuaciones perfectas mientras comprimía la caché por un factor de seis. A una precisión de 4 bits, el algoritmo ofreció hasta un aumento de velocidad de ocho veces en el cálculo de atención en GPUs Nvidia H100 en comparación con la línea base no comprimida de 32 bits.
Lo que escuchó el mercado
La reacción del mercado fue rápida y, en opinión de varios analistas, desproporcionada. El analista de Wells Fargo, Andrew Rocha, señaló que TurboQuant ataca directamente la curva de costos para la memoria en sistemas de IA. Si se adopta ampliamente, dijo, rápidamente plantea la cuestión de cuánta capacidad de memoria necesita realmente la industria. Pero Rocha y otros también advirtieron que la demanda de memoria para IA sigue siendo fuerte y que los algoritmos de compresión han existido durante años sin alterar fundamentalmente los volúmenes de adquisición.
Sin embargo, la preocupación no es infundada. El gasto en infraestructura de IA está creciendo a tasas extraordinarias, con Meta comprometiendo solo hasta $27 mil millones en un reciente acuerdo con Nebius para capacidad de computación dedicada, y Google, Microsoft y Amazon planeando colectivamente cientos de miles de millones en gastos de capital en centros de datos hasta 2026. Una tecnología que reduce los requisitos de memoria en seis veces no reduce el gasto en seis veces, porque la memoria es solo un componente del costo de un centro de datos. Pero cambia la proporción, y en una industria que gasta a esta escala, incluso las ganancias de eficiencia marginal se acumulan rápidamente.
La cuestión de la eficiencia
TurboQuant llega en un momento en que la industria de la IA se ve obligada a confrontar la economía de la inferencia. Entrenar un modelo es un costo único, por enorme que sea. Ejecutarlo, atendiendo millones de consultas por día con latencia y precisión aceptables, es el gasto recurrente que determina si los productos de IA son financieramente viables a gran escala. La caché de clave-valor es central para este cálculo: es el cuello de botella que limita cuántos usuarios concurrentes puede atender una sola GPU y cuánto tiempo puede soportar un modelo una ventana de contexto de manera práctica.
Las técnicas de compresión como TurboQuant son parte de un impulso más amplio hacia la reducción de costos de inferencia, junto con mejoras de hardware como la arquitectura Vera Rubin de Nvidia y los propios TPUs Ironwood de Google. La pregunta es si estas ganancias de eficiencia reducirán la cantidad total de hardware que la industria compra, o si simplemente permitirán implementaciones más ambiciosas a un costo aproximadamente igual. La historia de la computación sugiere lo último: cuando el almacenamiento se vuelve más barato, la gente almacena más; cuando el ancho de banda aumenta, las aplicaciones lo consumen.
Para Google, TurboQuant también tiene una aplicación comercial directa más allá de los modelos de lenguaje. El artículo del blog señala que el algoritmo mejora la búsqueda vectorial, la tecnología que impulsa las búsquedas de similitud semántica a través de miles de millones de elementos. Google lo probó contra métodos existentes en el conjunto de datos de referencia GloVe y encontró que lograba ratios de recuperación superiores sin requerir los grandes libros de códigos o la sintonización específica de conjuntos de datos que demandan los enfoques competidores. Esto es importante porque la búsqueda vectorial sustenta todo, desde Google Search hasta las recomendaciones de YouTube y la segmentación publicitaria, es decir, sustenta los ingresos de Google.
La contribución del artículo es real: un método de compresión sin entrenamiento que logra resultados mediblemente mejores que el estado del arte existente, con sólidas bases teóricas y una implementación práctica en hardware de producción. Si reconfigura la economía de la infraestructura de IA o simplemente se convierte en una optimización más absorbida por el insaciable apetito de la industria por la computación es una pregunta que el mercado responderá en meses, no en horas.
Otros artículos
 El TurboQuant de Google comprime la memoria de IA en 6x, sacude las acciones de chips.
El algoritmo TurboQuant de Google comprime las cachés de clave-valor de LLM a 3 bits sin pérdida de precisión. Las acciones de Memory cayeron en cuestión de horas tras el anuncio.
El TurboQuant de Google comprime la memoria de IA en 6x, sacude las acciones de chips.
El algoritmo TurboQuant de Google comprime las cachés de clave-valor de LLM a 3 bits sin pérdida de precisión. Las acciones de Memory cayeron en cuestión de horas tras el anuncio.
 Las nuevas GPU Arc Pro B70 y B65 de Intel están diseñadas para trabajos de IA.
Intel ha lanzado las GPU Arc Pro B70 y B65, diseñadas para inferencia de IA y cargas de trabajo profesionales, con hasta 32 GB de memoria GDDR6 y soporte completo para PCIe 5.0.
Las nuevas GPU Arc Pro B70 y B65 de Intel están diseñadas para trabajos de IA.
Intel ha lanzado las GPU Arc Pro B70 y B65, diseñadas para inferencia de IA y cargas de trabajo profesionales, con hasta 32 GB de memoria GDDR6 y soporte completo para PCIe 5.0.
 Una nueva aplicación quiere curar la soledad haciendo que las personas dejen sus teléfonos y se reúnan en la misma habitación.
Una startup llamada Friending ha lanzado una plataforma social construida alrededor de una premisa que suena casi anticuada en 2026: ayudar a las personas a hacer amigos al conocerse en persona. La aplicación, con sede en Raleigh, Carolina del Norte, conecta a los usuarios por intereses compartidos.
Una nueva aplicación quiere curar la soledad haciendo que las personas dejen sus teléfonos y se reúnan en la misma habitación.
Una startup llamada Friending ha lanzado una plataforma social construida alrededor de una premisa que suena casi anticuada en 2026: ayudar a las personas a hacer amigos al conocerse en persona. La aplicación, con sede en Raleigh, Carolina del Norte, conecta a los usuarios por intereses compartidos.
 Los Galaxy A57 y A37 de Samsung están aquí con nuevos chips y cámaras más inteligentes.
Los Galaxy A57 y A37 de Samsung son oficiales, trayendo nuevos procesadores Exynos, mejor fotografía nocturna y fundamentos familiares de gama media.
Los Galaxy A57 y A37 de Samsung están aquí con nuevos chips y cámaras más inteligentes.
Los Galaxy A57 y A37 de Samsung son oficiales, trayendo nuevos procesadores Exynos, mejor fotografía nocturna y fundamentos familiares de gama media.
 Esta podría ser nuestra primera mirada al próximo Galaxy Z Fold 8 de Samsung.
Las imágenes filtradas en CAD del Galaxy Z Fold 8 Wide revelan un plegable más ancho y corto que Samsung está construyendo específicamente para competir cara a cara con el primer iPhone plegable de Apple.
Esta podría ser nuestra primera mirada al próximo Galaxy Z Fold 8 de Samsung.
Las imágenes filtradas en CAD del Galaxy Z Fold 8 Wide revelan un plegable más ancho y corto que Samsung está construyendo específicamente para competir cara a cara con el primer iPhone plegable de Apple.
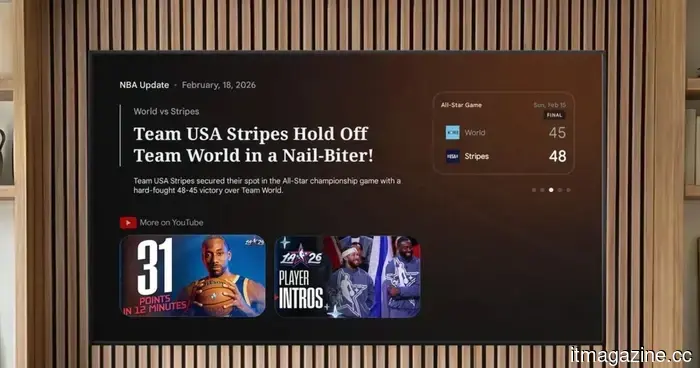 Gemini en Google TV ahora puede responder a tus preguntas, enseñar conceptos y ofrecer resúmenes deportivos.
Google está agregando funciones de Gemini a Google TV que te permiten hacer preguntas, explorar temas y mantenerte actualizado con resúmenes deportivos, todo en un solo lugar.
Gemini en Google TV ahora puede responder a tus preguntas, enseñar conceptos y ofrecer resúmenes deportivos.
Google está agregando funciones de Gemini a Google TV que te permiten hacer preguntas, explorar temas y mantenerte actualizado con resúmenes deportivos, todo en un solo lugar.
El TurboQuant de Google comprime la memoria de IA en 6x, sacude las acciones de chips.
El algoritmo TurboQuant de Google comprime las cachés de clave-valor de LLM a 3 bits sin pérdida de precisión. Las acciones de Memory cayeron en cuestión de horas tras el anuncio.