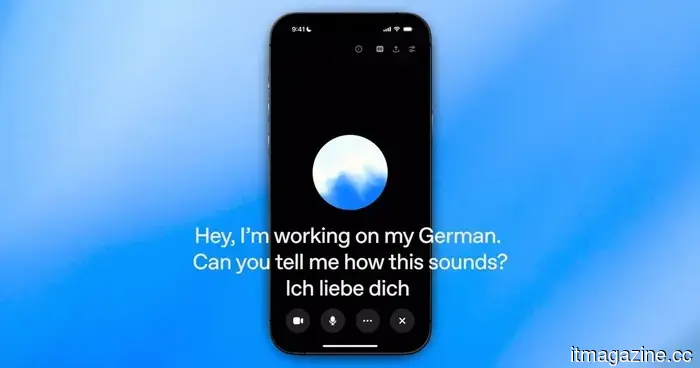
AI voice conversations often come across as uncomfortable because assistants struggle with timing their responses.
Thinking Machines Lab states it is developing full duplex AI, meaning an AI system can simultaneously listen to what someone is saying while crafting a response. To put it simply, it resembles a phone call more than a walkie-talkie.
The startup, which was established last year by former OpenAI CTO Mira Murati, has announced interaction models, beginning with TML-Interaction-Small. It claims the system can reply in 0.40 seconds, a speed that approaches typical human conversation rates.
However, there's a limitation for those eager to try it out today. It is still in a research preview phase, with restricted access anticipated in the coming months and a wider rollout expected later this year.
A quicker type of AI interaction
The fundamental concept is straightforward, and the alteration is significant. Rather than waiting for a person to complete their speech before formulating a response, the model interprets incoming speech while generating its answer.
This delay is crucial since pauses make AI assistants sound less natural. Thinking Machines Lab emphasizes that TML-Interaction-Small’s 0.40-second response time is nearly equivalent to natural conversation speed, which would represent a significant improvement for voice tools.
It also asserts that this speed exceeds that of similar models from OpenAI and Google. This benchmark lends credibility to the announcement, but external users must still verify if the experience operates as seamlessly as the figures suggest.
When speed impacts behavior
An assistant that replies while still receiving information alters users' expectations during a voice chat. Conversations can progress more quickly, but the system must also carefully manage timing.
This balance is essential when someone seeks a quick clarification rather than a lengthy generated response. Faster replies are ineffective if the assistant interrupts too early, misinterprets the speaker, or disrupts the intended flow.
For now, the architecture is the highlight. The actual product challenge lies in whether the interaction model can ensure that improved timing feels instinctive.
What to monitor before the launch
The release schedule is the crucial detail at this stage. Thinking Machines Lab has indicated that a limited research preview is forthcoming in the next few months, followed by broader availability later this year.
Details regarding accessibility, pricing, supported platforms, and performance beyond controlled settings remain uncertain. These factors are significant because a faster model is only beneficial if people can apply it in their everyday voice tools.
For users of AI voice assistants, the sensible approach is to closely observe the preview. Full duplex AI holds promise, but practical testing is necessary to determine whether quicker responses genuinely enhance everyday AI conversations.


Other articles
 How apprenticeship programs are broadening access to job opportunities
Craft Education and WGU are collaborating to broaden apprenticeship degree options that integrate paid employment, hands-on training, and academic advancement in areas such as education and nursing.
How apprenticeship programs are broadening access to job opportunities
Craft Education and WGU are collaborating to broaden apprenticeship degree options that integrate paid employment, hands-on training, and academic advancement in areas such as education and nursing.
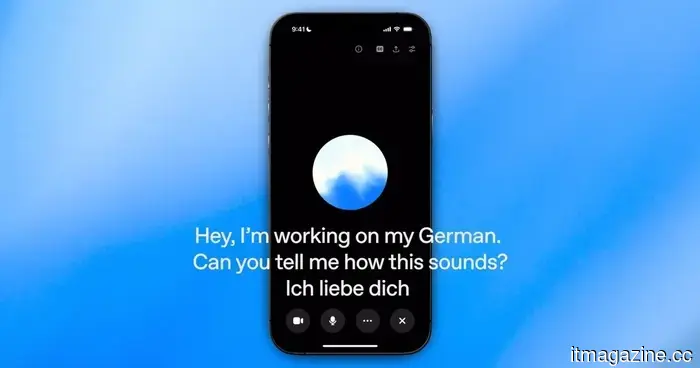 AI voice chats often feel uncomfortable because the assistants struggle to determine when to speak.
Thinking Machines Lab is experimenting with full duplex AI that can both listen and reply simultaneously, but the true evaluation will be whether quicker voice conversations feel beneficial when people get the chance to use them.
AI voice chats often feel uncomfortable because the assistants struggle to determine when to speak.
Thinking Machines Lab is experimenting with full duplex AI that can both listen and reply simultaneously, but the true evaluation will be whether quicker voice conversations feel beneficial when people get the chance to use them.
 OpenAI introduces Daybreak to compete with Anthropic’s Mythos in cyber defense.
OpenAI's newly launched Daybreak platform combines GPT-5.5 with Codex Security to compete against Anthropic's Mythos in AI-driven cybersecurity.
OpenAI introduces Daybreak to compete with Anthropic’s Mythos in cyber defense.
OpenAI's newly launched Daybreak platform combines GPT-5.5 with Codex Security to compete against Anthropic's Mythos in AI-driven cybersecurity.
 How apprenticeship programs are broadening access to job opportunities.
Craft Education and WGU are working together to broaden apprenticeship degree pathways that integrate paid employment, hands-on training, and academic advancement in areas such as teaching and nursing.
How apprenticeship programs are broadening access to job opportunities.
Craft Education and WGU are working together to broaden apprenticeship degree pathways that integrate paid employment, hands-on training, and academic advancement in areas such as teaching and nursing.
 Google has discovered the first zero-day exploit developed by AI and has successfully prevented a planned large-scale exploitation event.
Google's GTIG discovered the first zero-day exploit created with AI and prevented a widespread exploitation incident. The report indicates that state actors are leveraging AI for vulnerability research and autonomous malware development.
Google has discovered the first zero-day exploit developed by AI and has successfully prevented a planned large-scale exploitation event.
Google's GTIG discovered the first zero-day exploit created with AI and prevented a widespread exploitation incident. The report indicates that state actors are leveraging AI for vulnerability research and autonomous malware development.
 Nadella was concerned that Microsoft might end up being 'the next IBM' following the unveiling of a $92 billion return projection for OpenAI during the trial.
Microsoft CEO Satya Nadella stated during the Musk v. Altman trial that he was concerned his company might follow in IBM's footsteps. A memo from Brad Smith estimated that OpenAI's $13 billion investment could yield a $92 billion return.
Nadella was concerned that Microsoft might end up being 'the next IBM' following the unveiling of a $92 billion return projection for OpenAI during the trial.
Microsoft CEO Satya Nadella stated during the Musk v. Altman trial that he was concerned his company might follow in IBM's footsteps. A memo from Brad Smith estimated that OpenAI's $13 billion investment could yield a $92 billion return.
AI voice conversations often come across as uncomfortable because assistants struggle with timing their responses.
Thinking Machines Lab is evaluating full duplex AI capable of listening and responding simultaneously, but the true assessment will be how beneficial faster voice conversations seem once individuals have the opportunity to experience them.