
Google reports that AI chatbots are only 69% accurate, at most.
AI chatbots continue to provide inaccurate answers one-third of the time
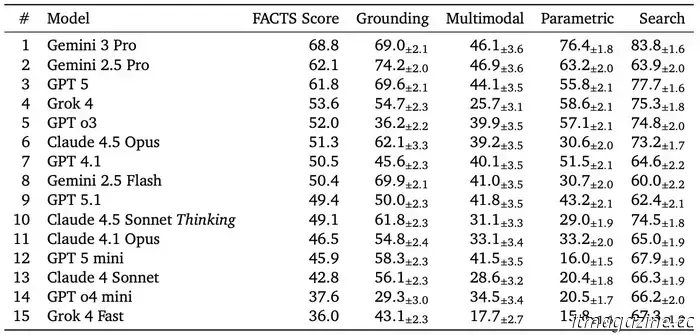
Google has released a straightforward evaluation regarding the reliability of current AI chatbots, and the findings are not particularly favorable. Utilizing its newly developed FACTS Benchmark Suite, the company discovered that even the leading AI models find it challenging to surpass a factual accuracy rate of 70%. The highest scorer, Gemini 3 Pro, achieved an overall accuracy of 69%, while other top models from OpenAI, Anthropic, and xAI recorded even lower results. The key takeaway is clear and somewhat troubling: these chatbots still deliver incorrect answers approximately one in three times, even when they respond with apparent confidence.
This benchmark is significant because most existing AI assessments primarily concentrate on whether a model can perform a task, rather than verifying the accuracy of the information it generates. In sectors like finance, healthcare, and law, this discrepancy can be costly. A fluent and confident-sounding response that contains inaccuracies can have serious repercussions, especially when users assume the chatbot is knowledgeable.
Insights from Google’s accuracy evaluation
Google
The FACTS Benchmark Suite was developed by Google’s FACTS team in collaboration with Kaggle to systematically assess factual accuracy across four practical applications. One test evaluates parametric knowledge, verifying if a model can answer fact-based questions using only information acquired during training. Another assesses search performance to determine how effectively models utilize web tools to access accurate data. A third test focuses on grounding, assessing whether the model adheres to a given document without introducing false information. The final evaluation scrutinizes multimodal understanding, which entails accurately interpreting charts, diagrams, and images.
Google
The findings illustrate significant variations among models. Gemini 3 Pro topped the rankings with a FACTS score of 69%, while Gemini 2.5 Pro and OpenAI’s ChatGPT-5 closely followed with nearly 62%. Claude 4.5 Opus scored around 51%, and Grok 4 achieved roughly 54%. The weakest performances were seen in multimodal tasks, often falling below the 50% accuracy threshold. This is particularly concerning as such tasks involve interpreting charts, diagrams, or images, where a chatbot may confidently misinterpret a sales graph or retrieve an incorrect figure from a document, leading to mistakes that could easily be overlooked and difficult to rectify.
The conclusion is not that chatbots lack utility, but rather that blind trust in them is hazardous. Data from Google indicates that while AI is progressing, it still requires verification, safeguards, and human oversight before being considered a truly reliable source of accurate information.



Other articles
 How sleep technology is transforming your nights
There’s nothing quite like waking up feeling exhausted and immediately pointing the finger at the closest inanimate object: the mattress. However, sleep technology has been evolving. It has been gradually making its way into the bedroom, altering how mattresses offer cooling, support, and responsiveness. Companies like Novilla are leading this advancement by creating mattresses that embrace a technology-driven approach.
How sleep technology is transforming your nights
There’s nothing quite like waking up feeling exhausted and immediately pointing the finger at the closest inanimate object: the mattress. However, sleep technology has been evolving. It has been gradually making its way into the bedroom, altering how mattresses offer cooling, support, and responsiveness. Companies like Novilla are leading this advancement by creating mattresses that embrace a technology-driven approach.
 Asus is now introducing the Nvidia GeForce RTX 5060 in two new variants.
Asus has introduced two new RTX 5060 variants that reimagine the card’s physical design while maintaining similar specifications. Designed for compact PC builders, the EVO variants feature slimmer profiles and updated connectors.
Asus is now introducing the Nvidia GeForce RTX 5060 in two new variants.
Asus has introduced two new RTX 5060 variants that reimagine the card’s physical design while maintaining similar specifications. Designed for compact PC builders, the EVO variants feature slimmer profiles and updated connectors.
 Microsoft Copilot subtly appears on LG TVs, and it cannot be removed.
Owners of LG TVs are finding Microsoft Copilot appearing on their home screens after a recent software update. The AI assistant installs itself automatically and cannot be deleted, demonstrating that AI functionalities are becoming integral components of smart TV systems.
Microsoft Copilot subtly appears on LG TVs, and it cannot be removed.
Owners of LG TVs are finding Microsoft Copilot appearing on their home screens after a recent software update. The AI assistant installs itself automatically and cannot be deleted, demonstrating that AI functionalities are becoming integral components of smart TV systems.
 NASA's 'Moonbound' generates excitement for its monumental Artemis II mission.
As NASA's first mission to the moon in fifty years approaches, possibly just a few months away, the space agency has launched the inaugural episode of a new series centered on this eagerly awaited endeavor. Titled "Moonbound – Charting the Course," the 22-minute episode provides an in-depth exploration of the ongoing preparations.
NASA's 'Moonbound' generates excitement for its monumental Artemis II mission.
As NASA's first mission to the moon in fifty years approaches, possibly just a few months away, the space agency has launched the inaugural episode of a new series centered on this eagerly awaited endeavor. Titled "Moonbound – Charting the Course," the 22-minute episode provides an in-depth exploration of the ongoing preparations.
 This small drone monitors, records, and follows you, and it now comes at a reasonable price.
If you’ve ever desired the sleek tracking shots and aerial views featured in travel vlogs and TikToks but prefer not to deal with a full-sized drone, this offer is definitely worth considering. The HOVERAir X1 PROMAX is a small, autonomous camera drone made to fit in your bag and take care of the filming for you. [...]
This small drone monitors, records, and follows you, and it now comes at a reasonable price.
If you’ve ever desired the sleek tracking shots and aerial views featured in travel vlogs and TikToks but prefer not to deal with a full-sized drone, this offer is definitely worth considering. The HOVERAir X1 PROMAX is a small, autonomous camera drone made to fit in your bag and take care of the filming for you. [...]
 You will soon have the ability to get iPhone notifications on a Galaxy smartwatch.
Apple has recently launched the initial beta version of iOS 26.3, which comes with a variety of new features for compatible iPhones. This update includes a new transfer tool intended to facilitate a smoother transition to an Android device, a Weather wallpaper section for customizing the lock screen, and, perhaps most importantly, the capability to view iPhone notifications on […]
You will soon have the ability to get iPhone notifications on a Galaxy smartwatch.
Apple has recently launched the initial beta version of iOS 26.3, which comes with a variety of new features for compatible iPhones. This update includes a new transfer tool intended to facilitate a smoother transition to an Android device, a Weather wallpaper section for customizing the lock screen, and, perhaps most importantly, the capability to view iPhone notifications on […]
Google reports that AI chatbots are only 69% accurate, at most.
Google's latest FACTS benchmark indicates that the leading AI chatbots currently achieve only around 69 percent accuracy. Even the top models, such as Gemini 3 Pro, make factual errors one-third of the time, which raises new concerns for businesses relying on the dependability of AI.