
Google encuentra que los chatbots de IA son precisos solo en un 69%... en el mejor de los casos
Los chatbots de IA todavía fallan en una de cada tres respuestas
Solen Feyissa / Unsplash
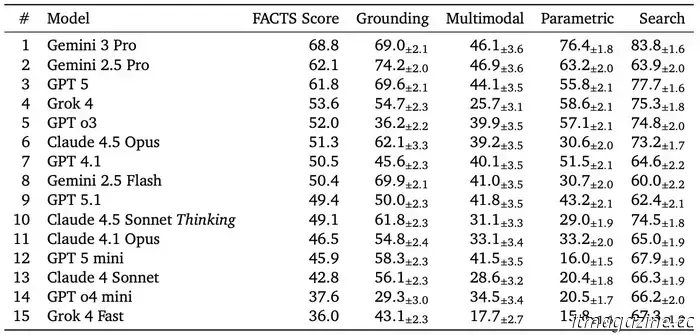
Google ha publicado una evaluación contundente sobre cuán fiables son realmente los chatbots de IA actuales, y los números no son halagüeños. Usando su recién introducido conjunto de referencia FACTS, la compañía encontró que incluso los mejores modelos de IA tienen dificultades para superar una tasa de precisión factual del 70%. El mejor colocado, Gemini 3 Pro, alcanzó un 69% de precisión global, mientras que otros sistemas líderes de OpenAI, Anthropic y xAI obtuvieron puntuaciones aún más bajas. La conclusión es simple y incómoda. Estos chatbots todavía dan aproximadamente una respuesta incorrecta de cada tres, incluso cuando suenan seguros al hacerlo.
El benchmark importa porque la mayoría de las pruebas de IA existentes se centran en si un modelo puede completar una tarea, no en si la información que produce es realmente verdadera. Para industrias como finanzas, salud y derecho, esa brecha puede ser costosa. Una respuesta fluida que suene segura pero contenga errores puede causar daños reales, especialmente cuando los usuarios asumen que el chatbot sabe de lo que habla.
Lo que revela la prueba de precisión de Google
Google
El conjunto de referencia FACTS fue creado por el equipo FACTS de Google junto con Kaggle para evaluar directamente la precisión factual en cuatro usos del mundo real. Una prueba mide el conocimiento paramétrico, que comprueba si un modelo puede responder preguntas basadas en hechos utilizando solo lo que aprendió durante el entrenamiento. Otra evalúa el rendimiento de búsqueda, probando qué tan bien los modelos usan herramientas web para recuperar información precisa. Una tercera se centra en el grounding, es decir, si el modelo se ciñe a un documento proporcionado sin añadir detalles falsos. La cuarta examina la comprensión multimodal, como leer correctamente gráficos, diagramas e imágenes.
Google
Los resultados muestran diferencias marcadas entre los modelos. Gemini 3 Pro encabezó la clasificación con un 69% en FACTS, seguido por Gemini 2.5 Pro y ChatGPT-5 de OpenAI, ambos cerca del 62%. Claude 4.5 Opus se situó en aproximadamente el 51%, mientras que Grok 4 obtuvo alrededor de un 54%. Las tareas multimodales fueron el área más débil en general, con precisiones a menudo por debajo del 50%. Esto importa porque estas tareas implican leer gráficos, diagramas o imágenes, donde un chatbot podría interpretar erróneamente con confianza un gráfico de ventas o extraer el número equivocado de un documento, lo que conduce a errores fáciles de pasar por alto pero difíciles de corregir.
La conclusión no es que los chatbots sean inútiles, sino que la confianza ciega es arriesgada. Los propios datos de Google sugieren que la IA está mejorando, pero aún necesita verificación, salvaguardas y supervisión humana antes de poder tratarse como una fuente fiable de verdad.
A Manisha le gusta cubrir la tecnología que forma parte de la vida cotidiana, desde teléfonos inteligentes y aplicaciones hasta juegos y streaming…
Encontré una herramienta para Mac que te encantará: un dock más estilizado con trucos extra
El dock del Mac se ha mantenido estático a lo largo de los años. Loopty lo reemplaza con mucho más estilo y utilidad.
El cambio a macOS Tahoe introdujo un montón de mejoras en los sistemas centrales del Mac. Spotlight, en particular, recibió algunos ajustes notables, como soporte para atajos personalizados y un sistema de búsqueda mejorado impulsado por IA. La desaparición de LaunchPad, sin embargo, resultó ser un cambio controvertido. Apple tampoco prestó atención a integraciones más profundas entre aplicaciones que han hecho que apps como RayCast sean muy populares en la comunidad de usuarios. El nuevo Spotlight quiere ser el centro de tus actividades principales en el Mac, pero no sin su buena dosis de desorden y algunas grandes omisiones.
Leer más
AMD jugará a lo seguro en el CES 2026, pero aún puede merecer tu atención
La presentación principal de AMD en el CES 2026 se perfila como algo mucho más centrado en la estrategia de IA que en nuevos chips de consumo llamativos.
Durante años, el Consumer Electronics Show (CES) ha evolucionado de una muestra de electrónica de consumo a una plataforma global de lanzamiento para fabricantes de chips, convirtiendo el evento en un campo de batalla clave por el liderazgo en informática y hardware de IA. Se espera que la edición de 2026 no sea menos.
AMD ha confirmado que la presidenta y CEO, la Dra. Lisa Su, dará la conferencia inaugural el 5 de enero, exponiendo la visión de la compañía sobre la IA en la nube, la empresa, el edge y los dispositivos de consumo. Aunque no esperamos anuncios importantes como una nueva generación de GPU o una sorpresa sobre Zen 6 (aunque siempre se puede soñar), se esperan algunos lanzamientos importantes.
Leer más
ChatGPT recibe una gran actualización (GPT-5.2) mientras OpenAI compite con Google en la carrera armamentista de la IA
La actualización GPT-5.2 de OpenAI mejora la productividad en el mundo real justo cuando Google intensifica la competencia con su último modelo Deep Research.
OpenAI ha lanzado oficialmente GPT-5.2, la última iteración de su serie de modelos de IA insignia y su respuesta a Gemini 3 de Google. El nuevo modelo pretende ser más rápido, más inteligente y más útil para las consultas complejas del mundo real, con mejoras en el razonamiento y en el procesamiento de documentos largos. Se está desplegando a los suscriptores de pago de ChatGPT como parte de los planes Plus, Pro, Team y Enterprise, y a desarrolladores vía API. OpenAI ofrece GPT-5.2 en tres variantes: GPT-5.2 Instant, GPT-5.2 Thinking y GPT-5.2 Pro (¿será cosa mía, o el nombre suena similar al de los modelos Gemini?).
Leer más



Otros artículos
 Cómo la tecnología del sueño está reescribiendo tu noche
Nada como despertarse cansado y culpar al instante al objeto inanimado más cercano: el colchón. Pero la tecnología del sueño no se ha quedado quieta. Se ha ido introduciendo en el dormitorio de forma sutil, cambiando la manera en que los colchones enfrían, brindan soporte y reaccionan ante ti. Marcas como Novilla son responsables de ese progreso, fabricando colchones con el mismo enfoque centrado en la tecnología que la gente […]
Cómo la tecnología del sueño está reescribiendo tu noche
Nada como despertarse cansado y culpar al instante al objeto inanimado más cercano: el colchón. Pero la tecnología del sueño no se ha quedado quieta. Se ha ido introduciendo en el dormitorio de forma sutil, cambiando la manera en que los colchones enfrían, brindan soporte y reaccionan ante ti. Marcas como Novilla son responsables de ese progreso, fabricando colchones con el mismo enfoque centrado en la tecnología que la gente […]
 Microsoft Copilot aparece silenciosamente en los televisores LG y no puedes eliminarlo.
Los propietarios de televisores LG están descubriendo Microsoft Copilot en sus pantallas de inicio tras una actualización de software. El asistente de IA se instala automáticamente y no puede ser eliminado, lo que pone de relieve cómo las funciones de IA se están convirtiendo cada vez más en partes permanentes de las plataformas de televisores inteligentes.
Microsoft Copilot aparece silenciosamente en los televisores LG y no puedes eliminarlo.
Los propietarios de televisores LG están descubriendo Microsoft Copilot en sus pantallas de inicio tras una actualización de software. El asistente de IA se instala automáticamente y no puede ser eliminado, lo que pone de relieve cómo las funciones de IA se están convirtiendo cada vez más en partes permanentes de las plataformas de televisores inteligentes.
 Ahora puedes ver Disney+ en tu visor Meta Quest sin necesidad de soluciones alternativas.
Disney+ ya dispone de una aplicación oficial para los visores Meta Quest, y los usuarios pueden transmitir contenido sin depender de un navegador ni de soluciones alternativas.
Ahora puedes ver Disney+ en tu visor Meta Quest sin necesidad de soluciones alternativas.
Disney+ ya dispone de una aplicación oficial para los visores Meta Quest, y los usuarios pueden transmitir contenido sin depender de un navegador ni de soluciones alternativas.
 La serie OnePlus Turbo llega para solucionar tus problemas con la batería y con los juegos.
OnePlus ha confirmado la serie OnePlus Turbo, prometiendo rendimiento de gama alta, una autonomía de batería sobresaliente y un enfoque centrado en los juegos a un precio más bajo. Las especificaciones, el precio y la fecha de lanzamiento aún se desconocen.
La serie OnePlus Turbo llega para solucionar tus problemas con la batería y con los juegos.
OnePlus ha confirmado la serie OnePlus Turbo, prometiendo rendimiento de gama alta, una autonomía de batería sobresaliente y un enfoque centrado en los juegos a un precio más bajo. Las especificaciones, el precio y la fecha de lanzamiento aún se desconocen.
 Pronto podrás recibir las notificaciones del iPhone en un Galaxy Watch.
Apple acaba de lanzar la primera versión beta de iOS 26.3, que introduce varias funciones nuevas que llegarán a los iPhones compatibles. La actualización añade una nueva herramienta de transferencia diseñada para que el cambio a un dispositivo Android sea mucho más fluido, una sección de fondos de pantalla del clima para la personalización de la pantalla de bloqueo y, lo más notable, compatibilidad para ver las notificaciones del iPhone en […]
Pronto podrás recibir las notificaciones del iPhone en un Galaxy Watch.
Apple acaba de lanzar la primera versión beta de iOS 26.3, que introduce varias funciones nuevas que llegarán a los iPhones compatibles. La actualización añade una nueva herramienta de transferencia diseñada para que el cambio a un dispositivo Android sea mucho más fluido, una sección de fondos de pantalla del clima para la personalización de la pantalla de bloqueo y, lo más notable, compatibilidad para ver las notificaciones del iPhone en […]
 «Moonbound» de la NASA genera expectación por su épica misión Artemis II
Con el primer lanzamiento de la NASA hacia la Luna en cinco décadas, que potencialmente podría producirse dentro de solo unos meses, la agencia espacial acaba de publicar el primer episodio de un nuevo programa que se centra en la tan esperada misión. Moonbound — Charting the Course dura 22 minutos y ofrece una inmersión profunda en los preparativos que se están llevando a cabo […]
«Moonbound» de la NASA genera expectación por su épica misión Artemis II
Con el primer lanzamiento de la NASA hacia la Luna en cinco décadas, que potencialmente podría producirse dentro de solo unos meses, la agencia espacial acaba de publicar el primer episodio de un nuevo programa que se centra en la tan esperada misión. Moonbound — Charting the Course dura 22 minutos y ofrece una inmersión profunda en los preparativos que se están llevando a cabo […]
Google encuentra que los chatbots de IA son precisos solo en un 69%... en el mejor de los casos
El nuevo benchmark FACTS de Google muestra que los mejores chatbots de IA actuales solo tienen aproximadamente un 69% de precisión. Incluso modelos de primer nivel como Gemini 3 Pro siguen dando datos incorrectos en un tercio de los casos, lo que genera nuevas preocupaciones para las empresas que apuestan por la fiabilidad de la IA.