
Il rilevamento dei deepfake migliora quando si utilizzano algoritmi più consapevoli della diversità demografica
I deepfakes - che consistono essenzialmente nel mettere le parole in bocca a qualcun altro in modo molto credibile - stanno diventando ogni giorno più sofisticati e sempre più difficili da individuare. Esempi recenti di deepfake sono le immagini di nudo di Taylor Swift, una registrazione audio del presidente Joe Biden che dice ai residenti del New Hampshire di non votare e un video del presidente ucraino Volodymyr Zelenskyy che invita le sue truppe a deporre le armi. Sebbene le aziende abbiano creato dei rilevatori per aiutare a individuare i deepfake, alcuni studi hanno scoperto che le distorsioni nei dati utilizzati per addestrare questi strumenti possono portare a colpire ingiustamente alcuni gruppi demografici.
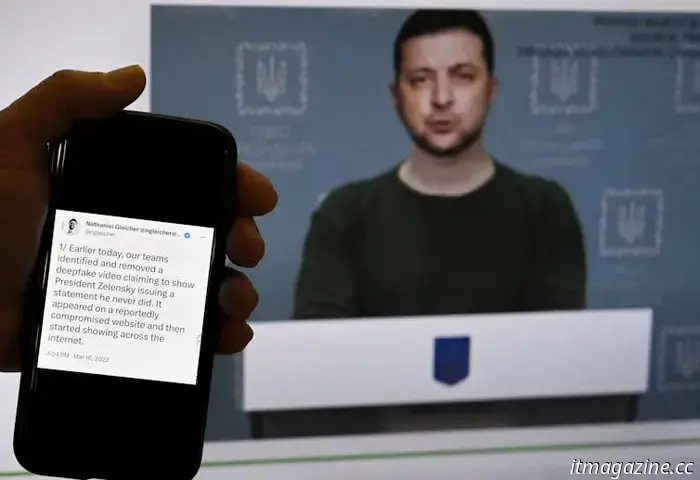
Un deepfake del presidente ucraino Volodymyr Zelensky nel 2022 mostrava il suo appello alle truppe a deporre le armi. Olivier Douliery/AFP via Getty Images Il mio team e io abbiamo scoperto nuovi metodi che migliorano l'equità e l'accuratezza degli algoritmi utilizzati per rilevare i deepfake. Per farlo, abbiamo utilizzato un ampio set di falsi facciali che consente ai ricercatori come noi di addestrare i nostri approcci di apprendimento profondo. Abbiamo costruito il nostro lavoro intorno all'algoritmo di rilevamento Xception, che è una base ampiamente utilizzata per i sistemi di rilevamento dei deepfake ed è in grado di rilevare i deepfake con un'accuratezza del 91,5%. Abbiamo creato due metodi distinti di rilevamento dei deepfake con l'obiettivo di incoraggiare l'equità. Uno si concentrava sul rendere l'algoritmo più consapevole della diversità demografica etichettando i set di dati in base al sesso e alla razza per ridurre al minimo gli errori tra i gruppi sottorappresentati. L'altro mirava a migliorare l'equità senza fare affidamento sulle etichette demografiche, concentrandosi invece su caratteristiche non visibili all'occhio umano. È risultato che il primo metodo ha funzionato meglio. Ha aumentato i tassi di accuratezza dal 91,5% di base al 94,17%, un incremento maggiore rispetto al nostro secondo metodo e a molti altri che abbiamo testato. Inoltre, ha aumentato l'accuratezza migliorando al contempo l'equità, che era il nostro obiettivo principale. Crediamo che l'equità e l'accuratezza siano fondamentali per far accettare al pubblico la tecnologia dell'intelligenza artificiale. Quando i modelli linguistici di grandi dimensioni come ChatGPT "hanno le allucinazioni", possono perpetuare informazioni errate. Allo stesso modo, le immagini e i video deepfake possono minare l'adozione dell'intelligenza artificiale se non possono essere individuati in modo rapido e accurato. Migliorare l'equità di questi algoritmi di rilevamento, in modo che alcuni gruppi demografici non ne siano danneggiati in modo sproporzionato, è un aspetto fondamentale. La nostra ricerca si occupa dell'equità degli algoritmi di rilevamento dei deepfake, piuttosto che del semplice tentativo di bilanciare i dati. Siwei Lyu, professore di informatica e ingegneria; direttore dell'UB Media Forensic Lab dell'Università di Buffalo e Yan Ju, dottorando in informatica e ingegneria dell'Università di Buffalo Questo articolo è stato ripubblicato da The Conversation con licenza Creative Commons. Leggi l'articolo originale. Ricevi la newsletter di TNW Ricevi le notizie tecnologiche più importanti nella tua casella di posta elettronica ogni settimana. Taggato anche con

Altri articoli
 L'ultimo volo del razzo di Blue Origin comprendeva un'esperienza simile a quella lunare
Per la prima volta, la società di voli spaziali guidata da Jeff Bezos ha simulato la gravità lunare su un razzo suborbitale per testare vari carichi scientifici.
L'ultimo volo del razzo di Blue Origin comprendeva un'esperienza simile a quella lunare
Per la prima volta, la società di voli spaziali guidata da Jeff Bezos ha simulato la gravità lunare su un razzo suborbitale per testare vari carichi scientifici.
 Xpeng batte Li Auto e diventa la startup cinese con il maggior numero di vendite di EV a gennaio
L'amministratore delegato di Xpeng, He Xiaopeng, ha dichiarato mercoledì di aspettarsi che le consegne annuali dell'azienda raddoppieranno quest'anno.
Xpeng batte Li Auto e diventa la startup cinese con il maggior numero di vendite di EV a gennaio
L'amministratore delegato di Xpeng, He Xiaopeng, ha dichiarato mercoledì di aspettarsi che le consegne annuali dell'azienda raddoppieranno quest'anno.
 L'NBA sta testando un nuovo pallone da basket intelligente prodotto in Europa
L'NBA sta sperimentando un pallone da basket intelligente realizzato da SportIQ, una startup finlandese che sviluppa sistemi di sensori per lo sport.
L'NBA sta testando un nuovo pallone da basket intelligente prodotto in Europa
L'NBA sta sperimentando un pallone da basket intelligente realizzato da SportIQ, una startup finlandese che sviluppa sistemi di sensori per lo sport.
 Le 12 migliori protezioni per lo schermo del Samsung Galaxy S25
Con la nuova linea Galaxy S25, Samsung inaugura quello che sarà senza dubbio un anno entusiasmante per gli smartphone. Tutti e tre i modelli sono dotati di una versione personalizzata del silicio più potente di Qualcomm, di una serie di nuove funzioni Galaxy AI e dei soliti splendidi display AMOLED.
Le 12 migliori protezioni per lo schermo del Samsung Galaxy S25
Con la nuova linea Galaxy S25, Samsung inaugura quello che sarà senza dubbio un anno entusiasmante per gli smartphone. Tutti e tre i modelli sono dotati di una versione personalizzata del silicio più potente di Qualcomm, di una serie di nuove funzioni Galaxy AI e dei soliti splendidi display AMOLED.
 I migliori film di fantascienza su Max in questo momento
I migliori film di fantascienza su Max includono Dredd, Valerian e la città dei 1000 pianeti, Time Bandits, Jupiter Ascending, Watchmen: Capitolo I e altri ancora.
I migliori film di fantascienza su Max in questo momento
I migliori film di fantascienza su Max includono Dredd, Valerian e la città dei 1000 pianeti, Time Bandits, Jupiter Ascending, Watchmen: Capitolo I e altri ancora.
 Un nuovo ministro del governo per l'IA deve ancora usare ChatGPT
Il ministro irlandese per la supervisione dell'IA promette di "imparare in fretta" su questa tecnologia trasformativa.
Un nuovo ministro del governo per l'IA deve ancora usare ChatGPT
Il ministro irlandese per la supervisione dell'IA promette di "imparare in fretta" su questa tecnologia trasformativa.
Il rilevamento dei deepfake migliora quando si utilizzano algoritmi più consapevoli della diversità demografica
Il software di rilevamento dei deepfake può prendere ingiustamente di mira persone appartenenti ad alcuni gruppi. I ricercatori hanno cercato di risolvere questo problema.