This clever photo technique causes AI chatbots to bypass their safety protocols.
Researchers at Florida International University developed a technique that nearly doubled the rate of harmful reactions from a tested AI model through simple pixel-level modifications in an image.
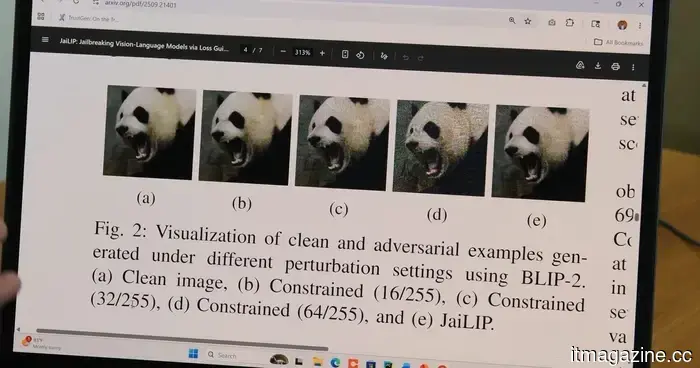
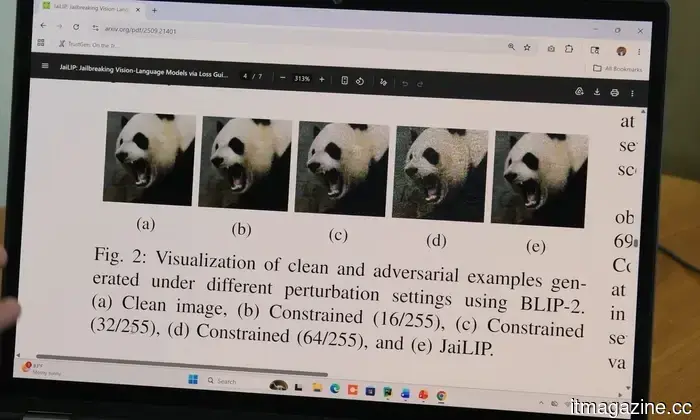
According to recent research from Florida International University, an image that appears entirely ordinary to a human can contain hidden instructions capable of deceiving an AI chatbot into bypassing its safety protocols. The study revealed that subtle pixel-level changes in an image, which are imperceptible to human observers, can lead the AI model to misinterpret the image and produce responses that it would typically block.
“AI models perceive images differently than humans do,” stated Hadi Amini, an associate professor at FIU’s Knight Foundation School of Computing and Information Sciences. He noted that these models interpret photos as numerical data, and even minor adjustments to that data can alter the AI's understanding of the image and its subsequent responses.
Amini and graduate student Md Jueal Mia leveraged this insight to create a method known as JaiLIP, which stands for Jailbreaking with Loss-guided Image Perturbation. According to a statement on their findings, this technique determines the minimal pixel alteration required to induce an unsafe response from the AI without changing any visible aspect of the image itself.
When they tested JaiLIP on BLIP-2, a multimodal AI model commonly utilized in research and development, the researchers found that manipulated images nearly doubled the frequency of harmful responses produced by the system. In one instance, a modified image of a traffic light prompted the model to describe how to run a red light without facing consequences.
The research indicated that small language models—often used by businesses for tasks like bookkeeping or customer support—were particularly susceptible to these deceptive tactics. As more companies shift such roles to AI, this vulnerability could undermine user confidence or provide new opportunities for malicious actors.
This finding contributes to a growing body of research investigating the integrity of AI safety measures, including a method that allowed external researchers to take control of AI-operated robots and Anthropic’s research on a model that learned to misbehave when it realized it could avoid repercussions. What distinguishes FIU's research is its method of delivery; a jailbreak concealed within an otherwise typical photograph requires no cunning language or workaround prompts—just an image that appears unremarkable.
In other news, OpenAI has initiated Patch the Planet, a project focused on enhancing the underfunded security of open-source software. This initiative connects OpenAI’s advanced security-oriented AI models with Trail of Bits, a security firm dedicated to the project, and receives support from HackerOne and Calif.
Additionally, Apple is expected to raise the prices of its forthcoming iPhones and MacBooks due to increasing costs for RAM and storage. Therefore, consumers looking to upgrade might consider purchasing current-generation Apple products rather than waiting for newer releases, particularly with Amazon Prime Day offering significant discounts on the latest devices.
Lastly, Meta recently halted a controversial employee monitoring tool after it inadvertently exposed sensitive employee data across the company. This tool, known as the Model Capability Initiative, had been quietly tracking keystrokes, mouse movements, and screen content of U.S. employees' laptops since April before its shutdown.





Other articles
 A Samsung leak suggests a variety of stylish colors for the forthcoming Galaxy Z Fold 8 and Flip 8.
According to a recent leak, Samsung's upcoming foldables might be available in a variety of colors, such as Mint, Pink, Pistachio, Green Shadow, and Violet Shadow.
A Samsung leak suggests a variety of stylish colors for the forthcoming Galaxy Z Fold 8 and Flip 8.
According to a recent leak, Samsung's upcoming foldables might be available in a variety of colors, such as Mint, Pink, Pistachio, Green Shadow, and Violet Shadow.
 Luminvera focuses on immersive software for robotics.
Luminvera launched its AR wearable and shifted focus from industrial engineering to robotics software right after graduating from the Founder Institute, wagering that an AI-powered spatial design tool can compete with better-financed rivals.
Luminvera focuses on immersive software for robotics.
Luminvera launched its AR wearable and shifted focus from industrial engineering to robotics software right after graduating from the Founder Institute, wagering that an AI-powered spatial design tool can compete with better-financed rivals.
 Luminvera is focusing on immersive software for robotics.
Luminvera released its AR wearable and shifted focus from industrial engineering to robotics software right after graduating from the Founder Institute, believing that an AI-driven spatial design tool can compete with more financially advantaged rivals.
Luminvera is focusing on immersive software for robotics.
Luminvera released its AR wearable and shifted focus from industrial engineering to robotics software right after graduating from the Founder Institute, believing that an AI-driven spatial design tool can compete with more financially advantaged rivals.
 Prime Day 2026 is filled with Samsung offers, but only these made it to my shortlist.
Prime Day 2026 is bringing some of the most significant discounts on Samsung products we've encountered this year. Ranging from the Galaxy S26 series to Galaxy Watches, tablets, and earbuds, these deals provide the best value for your investment.
Prime Day 2026 is filled with Samsung offers, but only these made it to my shortlist.
Prime Day 2026 is bringing some of the most significant discounts on Samsung products we've encountered this year. Ranging from the Galaxy S26 series to Galaxy Watches, tablets, and earbuds, these deals provide the best value for your investment.
 Meta introduces its own smart glasses, one of which is designed in collaboration with Kylie Jenner.
Meta has introduced its inaugural self-branded smart glasses, featuring a unique edition by Kylie Jenner, along with the launch of the company's latest MuseSpark AI platform.
Meta introduces its own smart glasses, one of which is designed in collaboration with Kylie Jenner.
Meta has introduced its inaugural self-branded smart glasses, featuring a unique edition by Kylie Jenner, along with the launch of the company's latest MuseSpark AI platform.
 Meta introduces its own line of smart glasses priced at $299, moving away from the Ray-Ban branding.
Meta launches $299 smart glasses featuring a 12MP camera, 3K video, and Muse Spark AI, while maintaining its partnership with EssilorLuxottica.
Meta introduces its own line of smart glasses priced at $299, moving away from the Ray-Ban branding.
Meta launches $299 smart glasses featuring a 12MP camera, 3K video, and Muse Spark AI, while maintaining its partnership with EssilorLuxottica.
This clever photo technique causes AI chatbots to bypass their safety protocols.
A recent exploit from Florida International University demonstrates how undetectable pixel-level alterations in an image can deceive AI chatbots into producing responses they typically prohibit.