Google introduces Gemini Omni Flash, a conversational model for video generation, although the avatar mode has been delayed.
The inaugural model in DeepMind's new Omni series will enable video generation and editing using a mix of image, audio, video, and text inputs. Speech editing features are currently not included, while SynthID watermarking is enabled by default.
On Tuesday, during the I/O 2026 developer conference, Google unveiled Gemini Omni, a new multimodal model family from Google DeepMind aimed at creating and editing videos from various input combinations. The first model in this series, Gemini Omni Flash, began rolling out the same day to the Gemini app and Google Flow for Google AI Plus, Pro, and Ultra subscribers, as well as to YouTube Shorts and the YouTube Create app at no cost. API access for developers and enterprise clients is expected to follow in the coming weeks.
Koray Kavukcuoglu, CTO of Google DeepMind and Chief AI Architect at Google, described Omni as a system that "integrates images, audio, video, and text to produce high-quality videos based on Gemini’s real-world insights." Users can combine different inputs within a single prompt.
Editing is conducted in a conversational manner, with each new instruction building on what was previously provided, ensuring continuity in character representation, physics, and scene context throughout the exchanges. The company mentioned that additional output formats, including image and audio generation, are anticipated in the future.
Omni’s marketing emphasizes three key points. Firstly, the model boasts a better intuitive grasp of physical principles, such as gravity, kinetic energy, and fluid dynamics, which enhances the accuracy of generated scenes. Secondly, it utilizes Gemini’s pre-existing knowledge to link language, images, and meanings beyond simple pattern recognition, as demonstrated with various prompts ranging from claymation explanations of protein folding to chain-reaction physics scenarios. Thirdly, the conversational editing feature maintains coherence across multi-turn revisions, which has historically been a challenge for previous video models regarding character identity and scene consistency.
The release also expands the Omni family to include digital avatar creation. These avatars enable users to record their own voice and likeness, allowing them to create videos that look and sound like themselves, with a setup process requiring users to record their voice while reciting a series of numbers.
For now, Google is specifically refraining from offering general-purpose audio and speech editing in Omni. According to Kavukcuoglu, this decision is part of ongoing tests to ensure that this capability is delivered responsibly, which has been interpreted by external coverage as a cautious move away from the murky domain of consent-free voice editing often associated with deepfakes.
All videos produced with Omni will include Google’s SynthID imperceptible digital watermark as a standard feature. Users can confirm if a video was created by Omni via the Gemini app, as well as through Gemini in Chrome and Google Search.
The SynthID system utilizes the same watermarking framework that OpenAI adopted earlier this year under the C2PA open standard, which is now regarded as the cross-industry standard for AI-generated visual provenance.
Regarding initial limitations, clips from the Flash tier are limited to 10 seconds at launch; this decision is due to deployment choices rather than constraints of the model itself. This limit is shorter than OpenAI's Sora maximum of 60 seconds, with Sora's spatiotemporal patch tokenization architecture being the closest comparable model.
Google has not yet revealed the cost structure per clip, the computing requirements for each generation, or the evaluation benchmarks used to compare Omni with Veo 3 or third-party models like ByteDance’s Seedance.
Omni is the focal point of a broader I/O 2026 announcement, which also introduced Gemini 3.5, and included Sundar Pichai's mention of the "agentic Gemini era" during his keynote. The main strategic discussion surrounding the announcement is whether the multi-input conversational editing process represents a genuinely new product category or simply a tighter integration of features that the broader frontier-video landscape has already shown.
The next indicator of progress will be the API launch for developers and enterprise clients in the upcoming weeks, which will clarify the pricing structure and maximum clip length in paid tiers.
What remains undisclosed is the model architecture of Omni in relation to Veo 3, the computational costs per generation, the pricing for clips beyond the Flash tier, benchmark results against DeepMind’s earlier video models, competing advanced offerings, and the timeline for the introduction of general-purpose audio and speech editing within the Omni family.
The avatar setup process and SynthID implementation primarily represent the company’s response to the consent and provenance concerns raised by the launch.
Other articles
 Dunia Innovations in Berlin invests €280 million in a GigaLab focused on autonomous AI materials.
Berlin's Dunia Innovations has announced plans for a €280 million, 6,000-square-meter GigaLab aimed at validating AI-created materials on an industrial level.
Dunia Innovations in Berlin invests €280 million in a GigaLab focused on autonomous AI materials.
Berlin's Dunia Innovations has announced plans for a €280 million, 6,000-square-meter GigaLab aimed at validating AI-created materials on an industrial level.
 Google Pomelli is now capable of creating your entire brand from the ground up.
Google Pomelli has become more intelligent. This AI marketing tool is now capable of creating your brand identity, generating brand books, and designing a full website for your small business.
Google Pomelli is now capable of creating your entire brand from the ground up.
Google Pomelli has become more intelligent. This AI marketing tool is now capable of creating your brand identity, generating brand books, and designing a full website for your small business.
 Meta initiates the 10% reduction, with the Singapore office receiving the notification at 4 am first.
On Wednesday, Meta began informing thousands of employees about layoffs, starting with staff in Singapore at 4 am local time. This job reduction follows a commitment made in April to decrease the workforce by approximately 8,000 positions.
Meta initiates the 10% reduction, with the Singapore office receiving the notification at 4 am first.
On Wednesday, Meta began informing thousands of employees about layoffs, starting with staff in Singapore at 4 am local time. This job reduction follows a commitment made in April to decrease the workforce by approximately 8,000 positions.
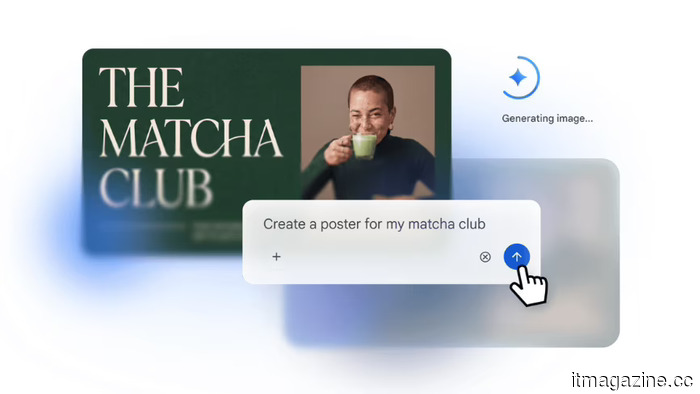 Google reveals Pics, an AI image generator integrated into Workspace, aimed at competing with Canva in precise editing.
Google has introduced Pics, an AI image generator integrated into Workspace, powered by Nano Banana 2. It features precision-editing controls and integrates with Slides and Drive.
Google reveals Pics, an AI image generator integrated into Workspace, aimed at competing with Canva in precise editing.
Google has introduced Pics, an AI image generator integrated into Workspace, powered by Nano Banana 2. It features precision-editing controls and integrates with Slides and Drive.
 Alibaba introduces the Zhenwu M890 as a strong competitor to NVIDIA in China's market.
Alibaba's T-Head chip division has introduced the Zhenwu M890, its most advanced AI accelerator to date, and announced that the chip has entered 'scaled mass production' as China intensifies its efforts to develop a domestic alternative to NVIDIA.
Alibaba introduces the Zhenwu M890 as a strong competitor to NVIDIA in China's market.
Alibaba's T-Head chip division has introduced the Zhenwu M890, its most advanced AI accelerator to date, and announced that the chip has entered 'scaled mass production' as China intensifies its efforts to develop a domestic alternative to NVIDIA.
Google introduces Gemini Omni Flash, a conversational model for video generation, although the avatar mode has been delayed.
Google has introduced Gemini Omni Flash, a novel multimodal video-generation model developed by DeepMind. This model allows for the conversational creation and editing of videos using image, audio, video, and text inputs, with SynthID watermarking enabled by default.