
Reasons why the EU's anonymization technique might not withstand the scrutiny of the GDPR.
Sergei Vassilvitskii, a prominent scientist at Google since 2012, has sent a letter to Brussels warning that the European Commission's proposed anonymisation approach for mandatory search data sharing is, as demonstrated by his team's research, breakable in just 120 minutes. The deadline for the decision is 27 July.
There is a well-known pattern of corporate grievance in EU regulatory processes: a US tech firm objects to a rule from Brussels, frames its objection as a safeguard for user interests, and is often dismissed by regulators as presenting a self-serving argument cloaked in concerns for privacy. The Reuters exclusive published on Tuesday complicates this dismissal.
Vassilvitskii, a highly cited researcher in the area of differential privacy at Google, has alerted the European Commission that the proposed anonymisation technique for enforced search-data sharing can be compromised in under two hours. He stated in his written comments to Reuters, which were republished in the wire service, “We are worried because the EC’s methodology for anonymisation does not adequately protect the privacy of Europeans: our red team was able to re-identify users in under two hours.”
This specific time frame is notable and, according to technical literature, credible.
What the EU is actually mandating
This situation arises within the framework of the Digital Markets Act (DMA), the EU’s leading competition regulation for so-called gatekeeper platforms. On January 27, 2026, the Commission initiated formal specification proceedings against Google based on Article 6(11) of the DMA, which requires gatekeeper search engines to provide third-party competitors with access to anonymised ranking, query, click, and view data on fair, reasonable, and non-discriminatory (FRAND) terms.
According to the Commission’s own press materials, this proceeding aims to specify four key elements: the range of data that must be shared, the anonymisation technique to be used, the conditions for access, and the eligibility of AI chatbot providers (such as OpenAI and Anthropic) to receive the data.
Google has until 27 July 2026 to comply. If it fails to do so, it may face DMA charges resulting in fines of up to 10% of its global annual revenue. The Register noted in mid-April that Google has accrued approximately €9.71 billion in European antitrust fines since 2017, making the stakes in this proceeding significant even by Google's standards.
What sets this proceeding apart is that the proposed solution, search data sharing, is privacy-sensitive in ways that most DMA remedies typically are not. The Information Technology and Innovation Foundation noted this core tension in a filing on May 1: mandating a search engine to disclose user-search data to competitors inherently increases the risk of user data exploitation.
The Chamber of Progress expressed similar concerns that same week, and CyberInsider cautioned that the proposal could lead to extensive surveillance if the anonymisation methods proved inadequate. Vassilvitskii’s comments provide a technical basis for these worries.
In current privacy discussions, anonymisation is not a simple characteristic of a dataset; rather, it is a probabilistic trait influenced by (a) the data itself, (b) the auxiliary information an attacker possesses, and (c) the anonymisation technique used. According to his Google Research profile, Vassilvitskii's work has principally focused on differential privacy, which is the mathematical framework for assessing and limiting re-identification risks in disclosed datasets. His paper scheduled for ACM SIGKDD in 2025 concerning differentially private datasets for Google’s Topics API stands as one of the more rigorously documented uses of this framework in a live commercial context.
The two-hour claim must be interpreted as an empirical assertion, not mere rhetoric. The red team, using search-engine query data anonymised according to the Commission's suggested method, succeeded in re-identifying individual users in under two hours. The proposed anonymisation approach, as Vassilvitskii frames it, is one of those methods (typically involving a mix of pseudonymisation, aggregation, and noise injection) that have been shown to be vulnerable to linkage attacks if the underlying queries are distinctive enough.
This vulnerability is not just theoretical. In 2006, an anonymised dataset from AOL led to multiple users being named within days, including a notorious case covered by the New York Times involving one particular user. The same principle is even more applicable to modern search data, which is now far more detailed than the 2006 dataset and easier to cross-reference against public online information.
Google now faces a complex political situation. The company has spent the last decade asserting that user privacy is one of its fundamental priorities, yet it is now involved in a Commission investigation compelling it to provide user data to competitors for competition purposes.
The assertion that such sharing would undermine user privacy, regardless of its technical accuracy, is subject to the counter-argument that Google's privacy concerns have arisen suspiciously
Other articles
 Peter Sarlin's Qutwo reaches a $380 million valuation in an angel funding round.
Qutwo, the company that orchestrates quantum and classical technologies and was established by Peter Sarlin from Silo AI, has achieved a valuation of $380 million in an angel investment round.
Peter Sarlin's Qutwo reaches a $380 million valuation in an angel funding round.
Qutwo, the company that orchestrates quantum and classical technologies and was established by Peter Sarlin from Silo AI, has achieved a valuation of $380 million in an angel investment round.
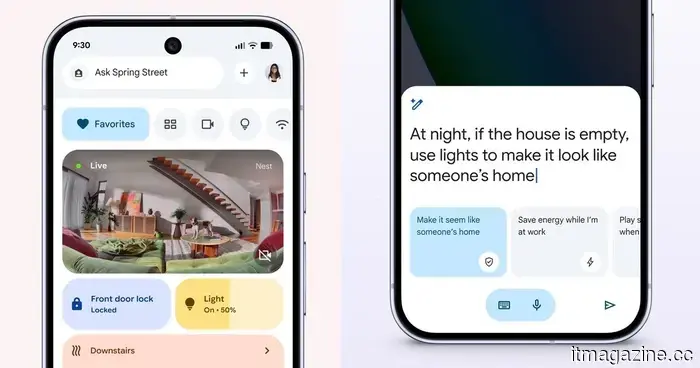 This Google Home update focuses on enhanced automation capabilities.
The Google Home update enhances automation by introducing new triggers, conditions, and actions, enabling more intelligent control over devices such as locks, lights, appliances, and sensors.
This Google Home update focuses on enhanced automation capabilities.
The Google Home update enhances automation by introducing new triggers, conditions, and actions, enabling more intelligent control over devices such as locks, lights, appliances, and sensors.
 You can now regain a bit of privacy with approximate location sharing in Chrome.
Chrome on Android now allows approximate location sharing, enabling users to restrict the accuracy with which websites can monitor their location while still providing necessary functionalities.
You can now regain a bit of privacy with approximate location sharing in Chrome.
Chrome on Android now allows approximate location sharing, enabling users to restrict the accuracy with which websites can monitor their location while still providing necessary functionalities.
 Davis secures $5.5 million in pre-seed funding to streamline real estate development.
Davis, located in Paris, has secured $5.5 million in pre-seed funding to streamline real estate development from months down to days, utilizing a new generative model named Gaudi-1.
Davis secures $5.5 million in pre-seed funding to streamline real estate development.
Davis, located in Paris, has secured $5.5 million in pre-seed funding to streamline real estate development from months down to days, utilizing a new generative model named Gaudi-1.
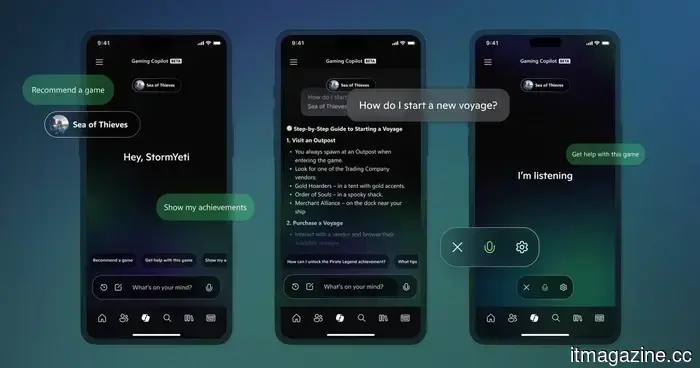 The CEO of Xbox has abandoned the Copilot AI initiative for consoles in order to concentrate on prioritizing gameplay experiences.
Microsoft has halted the development of Xbox Copilot AI for consoles and mobile, as CEO Asha Sharma redirects attention to enhancing player experience and core platform upgrades.
The CEO of Xbox has abandoned the Copilot AI initiative for consoles in order to concentrate on prioritizing gameplay experiences.
Microsoft has halted the development of Xbox Copilot AI for consoles and mobile, as CEO Asha Sharma redirects attention to enhancing player experience and core platform upgrades.
 DeepSeek's $45 billion valuation also serves as a strategic statement from Beijing.
China's Big Fund is currently in discussions to take the lead on DeepSeek's initial external funding round, valued at $45 billion, which is more than double the amount that was being considered a fortnight ago.
DeepSeek's $45 billion valuation also serves as a strategic statement from Beijing.
China's Big Fund is currently in discussions to take the lead on DeepSeek's initial external funding round, valued at $45 billion, which is more than double the amount that was being considered a fortnight ago.
Reasons why the EU's anonymization technique might not withstand the scrutiny of the GDPR.
Sergei Vassilvitskii, a scientist at Google, has alerted the European Commission that its method of anonymizing forced sharing of search data under the DMA can be compromised in under two hours.