
Reasons the EU's anonymization approach might not withstand the GDPR evaluation
Sergei Vassilvitskii, a notable scientist at Google since 2012, has reached out to Brussels to express concerns that the Commission’s proposed anonymisation scheme for mandated search-data sharing can be compromised in 120 minutes, as demonstrated by his red team. The deadline for a decision is set for 27 July.
A common theme appears in corporate complaints during EU regulatory discussions: a US tech firm challenges a Brussels regulation, positions the challenge as a safeguard for user welfare, and is subsequently dismissed by regulators who view it as a self-serving argument cloaked in privacy advocacy. The exclusive report by Reuters on Tuesday complicates this dismissal.
Vassilvitskii, recognized as one of the most-cited researchers in differential privacy, has alerted the European Commission that the proposed anonymisation method for coerced search-data sharing could be broken in under two hours. He stated in written comments to Reuters: “We are concerned because the EC’s approach to anonymisation fails to protect Europeans’ privacy: our red team was able to re-identify users in less than two hours.”
The specific timeline is strikingly precise and aligns well with technical literature.
The Objective of the EU Requirement
This issue emerges from the Digital Markets Act (DMA), the EU’s primary competition framework for what are termed gatekeeper platforms. On 27 January 2026, the Commission initiated formal specification proceedings against Google under Article 6(11) of the DMA, which mandates that gatekeeper search engines provide third-party competitors with access to anonymised ranking, query, click, and view data on fair, reasonable, and non-discriminatory (FRAND) terms.
According to the Commission’s own press materials, the intention of the proceedings is to clearly define four aspects: the range of data that must be shared, the anonymisation techniques that will be used, the access conditions, and the eligibility of AI chatbot providers (such as OpenAI and Anthropic) to receive this data.
Google's deadline for compliance is set for 27 July 2026, and failure to comply could lead to DMA charges with fines reaching up to 10 percent of the company's global annual revenue. Since 2017, Google has already faced approximately €9.71bn in European antitrust fines, illustrating that the financial stakes of this proceeding are significant, even by Google's standards.
What distinguishes this proceeding is that the suggested solution, the sharing of search data, presents privacy challenges that are uncommon in most DMA remedies. The Information Technology and Innovation Foundation raised a similar concern in a 1 May filing: compelling a search engine to disclose user-search data to competitors inherently increases the risk of user data exploitation.
The Chamber of Progress voiced similar issues that week, while CyberInsider cautioned that if the anonymisation methods are inadequate, it could facilitate widespread surveillance. Vassilvitskii's input provides a technical dimension to this concern.
In contemporary privacy discourse, anonymisation is viewed not as an absolute characteristic of a dataset, but rather as a probabilistic attribute influenced by (a) the data itself, (b) any additional information available to an attacker, and (c) the method of anonymisation. As per his Google Research profile, Vassilvitskii's studies have concentrated on differential privacy, which mathematically assesses and limits the risk of re-identification in shared datasets. His 2025 ACM SIGKDD paper on differentially private datasets for Google’s Topics API stands as one of the most rigorously documented applications of this framework in a real-world commercial context.
His claim regarding the two-hour timeframe is empirical rather than rhetorical. Vassilvitskii's red team successfully re-identified individual users within two hours from a sample of search-engine query data anonymised using the Commission's proposed method. In his view, the anonymisation technique proposed by the Commission falls under methods (often employing a mix of pseudonymisation, aggregation, and noise injection) that have been shown to be susceptible to linkage attacks, especially when the underlying queries are sufficiently unique.
This susceptibility is not merely theoretical; a 2006 anonymised release of AOL search data quickly allowed multiple users to be identified, including a well-known New York Times reconstruction of one user. This principle holds more starkly today, given that current search data is far more granular than that of the 2006 dataset and much easier to cross-reference against publicly available information.
A nuanced political challenge exists for Google. For the past ten years, the company has claimed that user privacy is among its primary commitments. Now, however, it faces a Commission proceeding that seeks to mandate the sharing of user data with competitors in the name of competition.
Arguing that such sharing would harm user privacy, regardless of its validity, opens Google up to accusations that its privacy concerns have coincidentally aligned with its commercial interests.
The Vassilvitskii intervention appears to be an effort to defuse this counterargument by
Other articles
 Peter Sarlin's Qutwo reaches a $380 million valuation in an angel funding round.
Qutwo, the company that orchestrates quantum and classical technologies and was established by Peter Sarlin from Silo AI, has achieved a valuation of $380 million in an angel investment round.
Peter Sarlin's Qutwo reaches a $380 million valuation in an angel funding round.
Qutwo, the company that orchestrates quantum and classical technologies and was established by Peter Sarlin from Silo AI, has achieved a valuation of $380 million in an angel investment round.
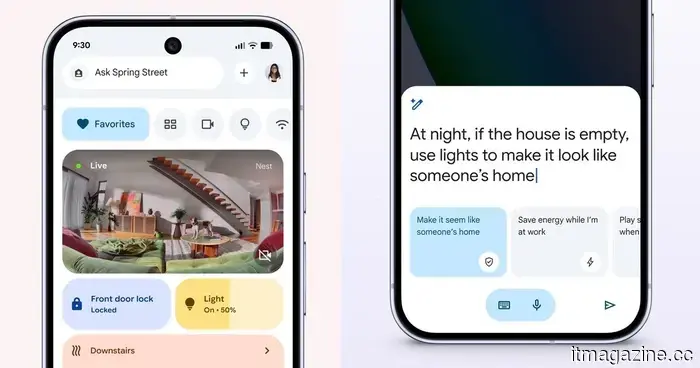 This update for Google Home focuses entirely on more intelligent automation.
The latest update for Google Home enhances automation by introducing new triggers, conditions, and actions, enabling more intelligent control of devices such as locks, lights, appliances, and sensors.
This update for Google Home focuses entirely on more intelligent automation.
The latest update for Google Home enhances automation by introducing new triggers, conditions, and actions, enabling more intelligent control of devices such as locks, lights, appliances, and sensors.
 DeepSeek's valuation of $45 billion serves as a strategic declaration from Beijing.
China's Big Fund is currently in discussions to spearhead DeepSeek's initial external funding round at $45 billion, which is more than twice the amount that was being considered two weeks prior.
DeepSeek's valuation of $45 billion serves as a strategic declaration from Beijing.
China's Big Fund is currently in discussions to spearhead DeepSeek's initial external funding round at $45 billion, which is more than twice the amount that was being considered two weeks prior.
 DeepSeek's $45 billion valuation also serves as a strategic statement from Beijing.
China's Big Fund is currently in discussions to take the lead on DeepSeek's initial external funding round, valued at $45 billion, which is more than double the amount that was being considered a fortnight ago.
DeepSeek's $45 billion valuation also serves as a strategic statement from Beijing.
China's Big Fund is currently in discussions to take the lead on DeepSeek's initial external funding round, valued at $45 billion, which is more than double the amount that was being considered a fortnight ago.
 Davis secures $5.5 million in pre-seed funding to streamline real estate development.
Davis, located in Paris, has secured $5.5 million in pre-seed funding to streamline real estate development from months down to days, utilizing a new generative model named Gaudi-1.
Davis secures $5.5 million in pre-seed funding to streamline real estate development.
Davis, located in Paris, has secured $5.5 million in pre-seed funding to streamline real estate development from months down to days, utilizing a new generative model named Gaudi-1.
 Davis secures $5.5 million in pre-seed funding to streamline real estate development.
Davis, based in Paris, has secured $5.5 million in pre-seed funding to accelerate real estate development from months to days using an innovative generative model named Gaudi-1.
Davis secures $5.5 million in pre-seed funding to streamline real estate development.
Davis, based in Paris, has secured $5.5 million in pre-seed funding to accelerate real estate development from months to days using an innovative generative model named Gaudi-1.
Reasons the EU's anonymization approach might not withstand the GDPR evaluation
Sergei Vassilvitskii, a scientist at Google, has alerted the European Commission that the anonymization technique used for mandatory search-data sharing under the DMA can be compromised in under two hours.