
Nvidia has launched the Nemotron 3 Nano Omni, an open multimodal model featuring 30 billion parameters, with 3 billion active, designed for edge AI agents.
**TL;DR**
Nvidia introduced Nemotron 3 Nano Omni, an open-weight multimodal model integrating vision, audio, and language within a single architecture, featuring 30 billion parameters with only 3 billion in use during each inference. It claims to deliver nine times the throughput compared to similar open models, excelling in six benchmark tests. Available under Nvidia’s Open Model Agreement for commercial purposes, this model aims for deployment in edge AI agents on single GPUs, positioning Nvidia not only in AI infrastructure but also in the models utilizing that infrastructure.
Nvidia unveiled Nemotron 3 Nano Omni on Tuesday, an open-weight multimodal AI model designed to combine vision, audio, and language comprehension within one architecture to enable autonomous AI agents on edge devices. While the model boasts 30 billion parameters, it activates only three billion during each forward pass through a mixture-of-experts approach. This design allows it to operate on a single GPU, achieving or surpassing the multimodal functionality of much larger models. Nvidia reports its performance is nine times higher than comparable open multimodal models that offer similar interactivity, providing 2.9 times quicker single-stream reasoning on multimodal tasks, and approximately nine times greater effective capacity for video reasoning. The model excels in six benchmarks related to document intelligence, video analysis, and audio understanding. It can process various inputs—text, images, audio, video, documents, charts, and graphical interfaces—yielding text output, which allows it to potentially replace the diverse specialized models typically used in enterprise AI deployments. This release, available on Hugging Face under Nvidia’s Open Model Agreement with full rights for commercial use, marks a significant strategic move for Nvidia as it shifts from merely selling AI infrastructure to offering AI models.
**The architecture**
Nemotron 3 Nano Omni features a hybrid Mamba-Transformer architecture, comprising 23 Mamba-2 selective state-space layers, 23 mixture-of-experts layers with 128 experts routing six per token along with a shared expert, and six grouped-query attention layers. Its vision encoder, C-RADIOv4-H, accommodates variable-resolution images, processing 16-by-16 patches with a range of 1,024 to 13,312 visual patches per image. The audio encoder, Parakeet-TDT-0.6B-v2, handles speech and environmental sound, while video processing employs three-dimensional convolutions to capture motion across frames instead of viewing video merely as a sequence of still images. The base text model was pretrained on 25 trillion tokens and supports a 256,000-token context window. This architecture reflects a deliberate design philosophy: to maximize capability per active parameter instead of total parameters since edge deployment limits are defined not by the model’s size at rest but by computational capacity per inference step. With three billion active parameters during inference, the model can operate on hardware revealed at Nvidia’s GTC 2026 developer conference, including the DGX Spark and DGX Station, without the need for extensive multi-GPU clusters that larger models in data centers require.
The mixture-of-experts strategy isn't a new concept, but its implementation in a multimodal model of this scale is. Many open multimodal models work with a single dense architecture that requires all parameters to be active at every inference step, or they utilize separate specialized models in a pipeline, resulting in latency during transitions. Nemotron 3 Nano Omni avoids both pitfalls. It directs each token to six of 128 experts within a cohesive model, allowing vision, audio, and text tokens to traverse the same architecture while activating distinct expertise based on the modality. Consequently, the model can simultaneously process a video feed, a spoken command, and a document without the inter-model lag that renders pipeline architectures impractical for real-time applications. For enterprise use, this simplifies the operational complexity of maintaining separate vision, speech, and language models along with distinct inference endpoints, monitoring, and versioning into a unified model serving a single endpoint.
**The strategy**
Nvidia has been focused on selling infrastructure during the AI boom: GPUs, networking, and the CUDA software ecosystem that integrates developers into its hardware. The Nemotron model family, which has seen over 50 million downloads in the last year, signifies an alternative strategy where Nvidia also delivers the models for that infrastructure. This creates a compelling circular logic: Nvidia’s models are tailor-made for Nvidia’s hardware, and vice versa, generating a comprehensive ecosystem that competes with the model-plus-cloud solutions from Google, Amazon, and Microsoft. The need for compact, domain-specific language models has been recognized in sectors such as education, healthcare, and enterprise. Nemotron 3 Nano Omni broadens this argument to multimodal applications, enabling enterprises to run a streamlined model locally rather than calling upon massive cloud models for every vision or audio task.
Initial enterprise usage includes companies like Foxconn, Palantir, Aible, ASI, Eka Care, and H Company, with others such as Dell
Other articles
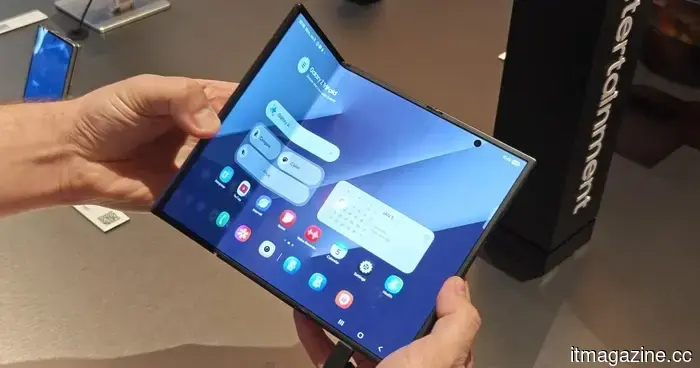 Samsung is facing a potential ban on its foldable phones in the US due to a patent conflict.
A recent lawsuit alleges that Samsung has violated foldable phone patents and is requesting a ban on sales in the US, although the allegations have not yet been substantiated.
Samsung is facing a potential ban on its foldable phones in the US due to a patent conflict.
A recent lawsuit alleges that Samsung has violated foldable phone patents and is requesting a ban on sales in the US, although the allegations have not yet been substantiated.
 Nvidia discreetly announced a new version of the GeForce RTX 5070 GPU within a driver blog post.
Nvidia's latest 12GB GeForce RTX 5070 Laptop GPU employs a different GDDR7 memory format to tackle supply issues, offering laptop manufacturers a third configuration option in addition to the current 8GB variant.
Nvidia discreetly announced a new version of the GeForce RTX 5070 GPU within a driver blog post.
Nvidia's latest 12GB GeForce RTX 5070 Laptop GPU employs a different GDDR7 memory format to tackle supply issues, offering laptop manufacturers a third configuration option in addition to the current 8GB variant.
 South Africa retreats from its national AI policy following the discovery that at least 6 out of 67 academic citations were identified as AI-generated fabrications.
South Africa withdrew its proposed AI policy after News24 discovered fabricated citations in actual journals. Minister Malatsi termed it an "unacceptable lapse." The integrity of the policy aimed at regulating AI was compromised by this issue.
South Africa retreats from its national AI policy following the discovery that at least 6 out of 67 academic citations were identified as AI-generated fabrications.
South Africa withdrew its proposed AI policy after News24 discovered fabricated citations in actual journals. Minister Malatsi termed it an "unacceptable lapse." The integrity of the policy aimed at regulating AI was compromised by this issue.
 Logitech’s latest G512 X gaming keyboard combines top-tier performance with extensive customization options.
Logitech's newest gaming keyboard offers PC gamers additional options to customize, adjust, and display their setup, including the responsiveness of each key.
Logitech’s latest G512 X gaming keyboard combines top-tier performance with extensive customization options.
Logitech's newest gaming keyboard offers PC gamers additional options to customize, adjust, and display their setup, including the responsiveness of each key.
 Google has entered into a classified agreement with the Pentagon regarding AI.
Google provided the Pentagon with classified access to Gemini for "any lawful purpose" just one day after over 580 employees voiced their protests. Additionally, it withdrew from a $100 million drone swarm competition following an ethics evaluation.
Google has entered into a classified agreement with the Pentagon regarding AI.
Google provided the Pentagon with classified access to Gemini for "any lawful purpose" just one day after over 580 employees voiced their protests. Additionally, it withdrew from a $100 million drone swarm competition following an ethics evaluation.
 GIGABYTE will release a thin laptop with AI for sale.
GIGABYTE, a well-known manufacturer of computer hardware, has announced the AERO X16 laptop. The new product is positioned as an ultra-thin device for those who need mobility, modern neural networks, and the ability to create something. It combines everything that is currently in vogue in one case.
GIGABYTE will release a thin laptop with AI for sale.
GIGABYTE, a well-known manufacturer of computer hardware, has announced the AERO X16 laptop. The new product is positioned as an ultra-thin device for those who need mobility, modern neural networks, and the ability to create something. It combines everything that is currently in vogue in one case.
Nvidia has launched the Nemotron 3 Nano Omni, an open multimodal model featuring 30 billion parameters, with 3 billion active, designed for edge AI agents.
Nvidia's Nemotron 3 Nano Omni integrates vision, audio, and text into a single open-weight model, achieving 9x throughput. Only 3 billion out of 30 billion parameters are utilized per step. It is designed for edge AI agents operating on individual GPUs.