
Claude Opus 4.7 outperforms GPT-5.4 and Gemini 3.1 Pro in SWE-bench and agentic reasoning.
In summary: Anthropic has unveiled Claude Opus 4.7, its most advanced model available to the public, demonstrating leading benchmark results on SWE-bench Pro (64.3% compared to GPT-5.4’s 57.7%), enabling multi-agent coordination for lengthy workflows, providing three times the image resolution, and showing a 14% enhancement in multi-step agentic reasoning while reducing tool errors by one-third. Priced at $5/$25 per million tokens, it can be accessed through Claude plans as well as Amazon Bedrock, Vertex AI, and Microsoft Foundry.
Claude Opus 4.7 is Anthropic's latest and most capable public model, boasting leading performance in software engineering and agentic reasoning, thereby widening the gap between itself and both OpenAI’s GPT-5.4 and Google’s Gemini 3.1 Pro on critical tasks for developers and enterprise users.
This release coincides with significant commercial momentum for Anthropic, which is operating at an annual revenue rate of $30 billion, receiving investor offers around $800 billion, and engaging in preliminary IPO discussions. Opus 4.7 must validate these figures, not by excelling in every benchmark, but by becoming the preferred model for enterprises and developers.
Key Developments
The standout metrics are in software engineering. On SWE-bench Pro, which assesses a model’s capacity to tackle real-world software challenges from open-source repositories, Opus 4.7 achieves 64.3%, an increase from 53.4% on Opus 4.6, significantly outpacing GPT-5.4 at 57.7% and Gemini 3.1 Pro at 54.2%. In SWE-bench Verified, a specially curated subset, it scores 87.6%, compared to 80.8% for its predecessor and 80.6% for Gemini 3.1 Pro.
CursorBench, which evaluates autonomous coding efficiency in a widely used AI code editor, reflects a similar rise: 70%, up from 58% on Opus 4.6. Given that the model is already the standard in Cursor and Claude Code, this improvement on a benchmark directly linked to developer usage is noteworthy. Claude Code had an annualized revenue of $2.5 billion in February, making AI-assisted coding one of the fastest-growing areas in software.
Regarding graduate-level reasoning, assessed by GPQA Diamond, the top models have reached a similar level of performance. Opus 4.7 scores 94.2%, GPT-5.4 Pro scores 94.4%, and Gemini 3.1 Pro scores 94.3%. The differences are negligible. The leading models have effectively saturated this benchmark, indicating that competition is now focusing less on raw reasoning scores and more on practical performance in complex, multi-step tasks.
Significant Advancements
The most impactful enhancements of Opus 4.7 may not be reflected in a single benchmark. Anthropic cites a 14% improvement over Opus 4.6 for intricate multi-step workflows, utilizing fewer tokens and generating one-third of the tool errors. It is the first Claude model adept at what Anthropic labels “implicit-need tests,” where the model must deduce necessary tools or actions without explicit instructions.
The model also incorporates multi-agent coordination, enabling the orchestration of parallel AI workflows instead of handling tasks one after another. For enterprise users utilizing Claude for activities like code review, document analysis, and data processing simultaneously, this capability translates directly to increased productivity. Anthropic claims that Opus 4.7 is designed to maintain focus during extended workflows, possibly addressing one of the main criticisms of leading models: their tendency to lose coherence and precision with lengthy agentic tasks.
Resilience is another focal point. The model is built to continue functioning through tool failures that would have halted Opus 4.6, managing to recover and adapt rather than coming to a stop. In automated pipelines where a single failure can trigger a cascade of issues, this robustness is more significant than slight benchmark improvements.
Enhanced Vision and Context
Opus 4.7 can process images at resolutions up to 2,576 pixels on the longer side, which is over three times the capability of previous Claude models. This enhancement is particularly aimed at enterprise document analysis, where detailed elements in scanned contracts, technical drawings, and financial statements can be overlooked or misrepresented by lower-resolution vision models.
The context window remains at one million tokens, which is half of Gemini 3.1 Pro’s two million but is adequate for most enterprise applications. In long-context research benchmarks, Opus 4.7 achieved the highest overall score of 0.715 across six research modules, providing what evaluators described as the most consistent long-context performance of any tested model.
Anthropic highlights that the model adheres more strictly to instructions than earlier versions, which may necessitate users to modify existing prompts. This represents
Other articles
 Tesla is considering its Shanghai Gigafactory for the mass production of the Optimus humanoid robot.
The president of Tesla China refers to the Shanghai Gigafactory as a "golden key" for the production of the Optimus robot, with the facility that produces half of Tesla's vehicles now looking toward humanoid manufacturing.
Tesla is considering its Shanghai Gigafactory for the mass production of the Optimus humanoid robot.
The president of Tesla China refers to the Shanghai Gigafactory as a "golden key" for the production of the Optimus robot, with the facility that produces half of Tesla's vehicles now looking toward humanoid manufacturing.
 Microsoft leaks suggest what many expected: the Surface lineup lacks a response to the MacBook Neo.
Leaked details about Microsoft's Surface lineup for 2026 indicate enhancements in display technology and a phased introduction of chips; however, the company still lacks offerings for consumers considering Apple's MacBook Neo.
Microsoft leaks suggest what many expected: the Surface lineup lacks a response to the MacBook Neo.
Leaked details about Microsoft's Surface lineup for 2026 indicate enhancements in display technology and a phased introduction of chips; however, the company still lacks offerings for consumers considering Apple's MacBook Neo.
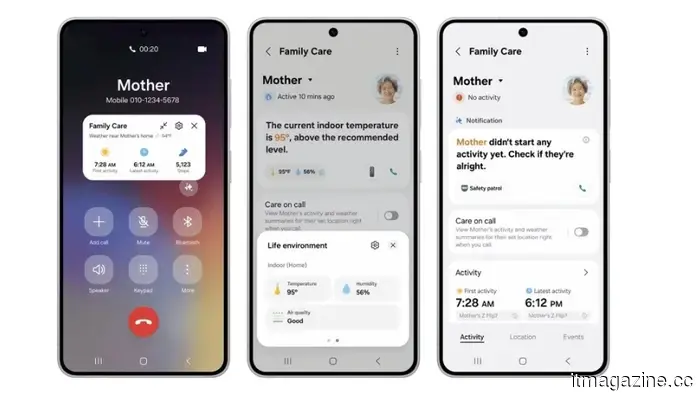 The latest Samsung SmartThings update introduces monitoring features for elderly care, incorporating ambient sensing and artificial intelligence.
Samsung's SmartThings update utilizes robot vacuums, home appliances, and wearable devices to keep an eye on elderly family members, identify falls and signs of cognitive decline, and notify caregivers from a distance.
The latest Samsung SmartThings update introduces monitoring features for elderly care, incorporating ambient sensing and artificial intelligence.
Samsung's SmartThings update utilizes robot vacuums, home appliances, and wearable devices to keep an eye on elderly family members, identify falls and signs of cognitive decline, and notify caregivers from a distance.
 Google incorporates Nano Banana image creation into the Personal Intelligence feature of Gemini.
Google's Gemini is now capable of creating images using personal context from Gmail, Photos, and Drive through Nano Banana, with the feature being rolled out to subscribers in the US, while Europe is not included.
Google incorporates Nano Banana image creation into the Personal Intelligence feature of Gemini.
Google's Gemini is now capable of creating images using personal context from Gmail, Photos, and Drive through Nano Banana, with the feature being rolled out to subscribers in the US, while Europe is not included.
 Solidroad secures $25 million in Series A funding to enhance customer support quality assurance through AI automation.
Solidroad, established by former Intercom employees, has secured $25 million in funding from Hedosophia to implement AI quality assurance across all customer support interactions for clients such as Ryanair and Crypto.com.
Solidroad secures $25 million in Series A funding to enhance customer support quality assurance through AI automation.
Solidroad, established by former Intercom employees, has secured $25 million in funding from Hedosophia to implement AI quality assurance across all customer support interactions for clients such as Ryanair and Crypto.com.
 Tesla is considering its Shanghai Gigafactory for the mass production of the Optimus humanoid robot.
The president of Tesla in China refers to the Shanghai Gigafactory as a "golden key" for the production of the Optimus robot, as the facility that produces half of Tesla's vehicles looks to venture into humanoid manufacturing.
Tesla is considering its Shanghai Gigafactory for the mass production of the Optimus humanoid robot.
The president of Tesla in China refers to the Shanghai Gigafactory as a "golden key" for the production of the Optimus robot, as the facility that produces half of Tesla's vehicles looks to venture into humanoid manufacturing.
Claude Opus 4.7 outperforms GPT-5.4 and Gemini 3.1 Pro in SWE-bench and agentic reasoning.
Anthropic's Claude Opus 4.7 achieves a score of 64.3% on SWE-bench Pro, introduces multi-agent coordination and features three times the vision resolution, while maintaining the same pricing as the previous version.