
Claude Opus 4.7 guida su SWE-bench e ragionamento agentico, battendo GPT-5.4 e Gemini 3.1 Pro
In breve: Anthropic ha rilasciato Claude Opus 4.7, il suo modello più capace generalmente disponibile, con punteggi leader nel benchmark su SWE-bench Pro (64,3% contro il 57,7% di GPT-5.4), coordinazione multi-agente per flussi di lavoro di ore, risoluzione delle immagini 3 volte superiore e un miglioramento del 14% nel ragionamento agentico multi-passaggio con un terzo degli errori dello strumento. Prezzo di $5/$25 per milione di token, è disponibile nei piani Claude e attraverso Amazon Bedrock, Vertex AI e Microsoft Foundry.
Anthropic ha rilasciato Claude Opus 4.7, il suo modello più capace generalmente disponibile fino ad oggi, con prestazioni leader nel benchmark nel software engineering e nel ragionamento agentico che amplia il divario tra Claude e sia GPT-5.4 di OpenAI che Gemini 3.1 Pro di Google sui compiti che contano di più per sviluppatori e utenti aziendali.
Il rilascio avviene in un momento in cui il momentum commerciale di Anthropic è difficile da sovrastimare. L'azienda sta operando a un tasso di fatturato annualizzato di 30 miliardi di dollari, ha attratto offerte da investitori a circa 800 miliardi di dollari ed è in fase di colloqui per un'IPO anticipata. Opus 4.7 è il modello che deve giustificare quei numeri, non vincendo ogni benchmark, ma essendo il modello che le aziende e gli sviluppatori scelgono per costruire.
Dove conduce
I numeri principali sono nel software engineering. Su SWE-bench Pro, il benchmark che testa la capacità di un modello di risolvere problemi software reali da repository open-source, Opus 4.7 ottiene il 64,3%, in aumento rispetto al 53,4% di Opus 4.6 e ben oltre il 57,7% di GPT-5.4 e il 54,2% di Gemini 3.1 Pro. Su SWE-bench Verified, un sottoinsieme curato, il punteggio è dell'87,6%, rispetto all'80,8% del suo predecessore e all'80,6% di Gemini 3.1 Pro.
CursorBench, che misura le prestazioni di codifica autonoma nel popolare editor di codice AI, mostra un salto simile: 70%, in aumento dal 58% di Opus 4.6. Per un modello che è già la scelta predefinita in Cursor e Claude Code, il miglioramento sul benchmark più direttamente legato a come gli sviluppatori lo utilizzano effettivamente è significativo. Solo Claude Code ha raggiunto 2,5 miliardi di dollari di fatturato annualizzato a febbraio, e la codifica assistita da AI è diventata una delle categorie in più rapida crescita nel software.
Nel ragionamento a livello di laurea, misurato da GPQA Diamond, il campo si è convergente. Opus 4.7 ottiene il 94,2%, GPT-5.4 Pro ottiene il 94,4% e Gemini 3.1 Pro ottiene il 94,3%. Le differenze sono all'interno del rumore. I modelli di frontiera hanno effettivamente saturato questo benchmark, il che significa che la differenziazione competitiva si sta spostando lontano dai punteggi di ragionamento grezzo e verso le prestazioni applicate su compiti complessi e multi-passaggio.
Il passo agentico
I miglioramenti più significativi di Opus 4.7 potrebbero non essere catturati da alcun singolo benchmark. Anthropic afferma che il modello offre un miglioramento del 14% rispetto a Opus 4.6 su flussi di lavoro complessi a più passaggi, utilizzando meno token e producendo un terzo degli errori dello strumento. È il primo modello Claude a superare quelli che Anthropic chiama "test di necessità implicita", compiti in cui il modello deve inferire quali strumenti o azioni sono richiesti piuttosto che essere informato esplicitamente.
Il modello introduce anche la coordinazione multi-agente, la capacità di orchestrare flussi di lavoro AI paralleli piuttosto che elaborare compiti in sequenza. Per gli utenti aziendali che eseguono Claude su revisione del codice, analisi dei documenti e elaborazione dei dati simultaneamente, questo è il tipo di capacità che si traduce direttamente in produttività. Anthropic afferma che Opus 4.7 è progettato per mantenere la concentrazione su flussi di lavoro di ore, un'affermazione che, se valida, affronta una delle lamentele più comuni sui modelli di frontiera: che perdono coerenza e precisione su compiti agentici estesi.
La resilienza è un altro punto di enfasi. Il modello è progettato per continuare a eseguire attraverso guasti degli strumenti che avrebbero fermato Opus 4.6, recuperando e adattandosi piuttosto che fermarsi. Per pipeline automatizzate in cui un singolo guasto può avere effetti a cascata, questo tipo di robustezza conta più dei guadagni marginali nei benchmark.
Visione e contesto
Opus 4.7 elabora immagini a risoluzioni fino a 2.576 pixel sul lato lungo, più di tre volte la capacità dei precedenti modelli Claude. Il miglioramento è mirato all'analisi dei documenti aziendali, dove contratti scansionati, disegni tecnici e bilanci spesso contengono caratteri piccoli e dettagli che i modelli di visione a bassa risoluzione perdono o allucinano.
La finestra di contesto rimane a un milione di token, la metà dei due milioni di Gemini 3.1 Pro ma sufficiente per la maggior parte dei casi d'uso aziendali. Su benchmark di ricerca a lungo contesto, Opus 4.7 si è classificato per il punteggio complessivo più alto a 0,715 su sei moduli di ricerca e ha fornito ciò che i valutatori hanno descritto come le prestazioni a lungo contesto più coerenti di qualsiasi modello testato.
Anthropic osserva che il modello segue le istruzioni in modo più letterale rispetto ai suoi predecessori, un cambiamento che potrebbe richiedere agli utenti di adattare i prompt esistenti. Questo è un compromesso: un seguito delle istruzioni più rigoroso riduce l'ambiguità che a volte produce output creativi o inaspettati, ma riduce anche l'allucinazione e il comportamento fuori tema che frustra le implementazioni aziendali.
Prezzi e disponibilità
Opus 4.7 è disponibile immediatamente sui piani Claude Pro, Max, Team ed Enterprise, e attraverso l'API a $5 per milione di token di input e $25 per milione di token di output. La memorizzazione nella cache dei prompt offre risparmi sui costi fino al 90%, e l'API Batch fornisce uno sconto del 50% sia sugli input che sugli output. Il modello è anche disponibile attraverso Amazon Bedrock, Vertex AI di Google Cloud e Microsoft Foundry.
I prezzi non sono cambiati rispetto a Opus 4.6, il che significa che Anthropic sta offrendo prestazioni sostanzialmente migliori allo stesso costo. Gemini 3.1 Pro lo sottocosta a $2 e $12 per milione di token per input e output rispettivamente, ma il vantaggio di Opus 4.7 sui benchmark che interessano gli acquirenti aziendali, in particolare SWE-bench e ragionamento agentico, potrebbe giustificare il premio per i clienti le cui carichi di lavoro richiedono la massima capacità.
Anthropic ha anche aggiunto misure di sicurezza informatica che rilevano e bloccano automaticamente le richieste che indicano usi proibiti o ad alto rischio per la sicurezza informatica, un cenno alle preoccupazioni sull'uso duale che hanno portato l'azienda a limitare il suo modello Mythos più potente a sole 11 organizzazioni sotto il Progetto Glasswing.
Cosa significa
Opus 4.7 non è un cambiamento di paradigma. È un miglioramento significativo in ogni dimensione che conta per le persone che pagano per Claude: migliore codifica, migliore ragionamento agentico, migliore visione, migliore seguito delle istruzioni e migliore resilienza su compiti lunghi. Il modello non vince ogni benchmark contro ogni concorrente, ma vince in modo convincente su quelli più direttamente legati alla produttività nel mondo reale.
Per Anthropic, il rilascio rafforza la posizione che ha guidato la sua straordinaria crescita dei ricavi. Claude è il modello che sviluppatori e aziende scelgono quando hanno bisogno di output affidabili e di alta qualità su lavori complessi. Opus 4.7 estende quel vantaggio in un momento in cui la traiettoria commerciale dell'azienda dipende da esso. La concorrenza è vicina e in chius
Altri articoli
 Le fughe di notizie di Microsoft prevedono l'ovvio: la linea Surface non ha risposta per il MacBook Neo
Piani trapelati per la linea Surface di Microsoft del 2026 mostrano aggiornamenti del display e un rilascio del chip in due fasi, ma l'azienda non ha ancora nulla per gli acquirenti che guardano al MacBook Neo di Apple.
Le fughe di notizie di Microsoft prevedono l'ovvio: la linea Surface non ha risposta per il MacBook Neo
Piani trapelati per la linea Surface di Microsoft del 2026 mostrano aggiornamenti del display e un rilascio del chip in due fasi, ma l'azienda non ha ancora nulla per gli acquirenti che guardano al MacBook Neo di Apple.
 Solidroad raccoglie 25 milioni di dollari in un round di finanziamento di Serie A per automatizzare il controllo qualità del supporto clienti con l'IA.
Solidroad, fondata da ex-alunni di Intercom, raccoglie 25 milioni di dollari da Hedosophia per applicare l'assicurazione qualità AI al 100% delle interazioni di supporto clienti per clienti tra cui Ryanair e Crypto.com.
Solidroad raccoglie 25 milioni di dollari in un round di finanziamento di Serie A per automatizzare il controllo qualità del supporto clienti con l'IA.
Solidroad, fondata da ex-alunni di Intercom, raccoglie 25 milioni di dollari da Hedosophia per applicare l'assicurazione qualità AI al 100% delle interazioni di supporto clienti per clienti tra cui Ryanair e Crypto.com.
 Le fughe di notizie di Microsoft prevedono l'ovvio: la linea Surface non ha risposta per il MacBook Neo.
Piani trapelati per la linea Surface di Microsoft del 2026 mostrano aggiornamenti del display e un rilascio del chip in due fasi, ma l'azienda non ha ancora nulla per gli acquirenti che guardano al MacBook Neo di Apple.
Le fughe di notizie di Microsoft prevedono l'ovvio: la linea Surface non ha risposta per il MacBook Neo.
Piani trapelati per la linea Surface di Microsoft del 2026 mostrano aggiornamenti del display e un rilascio del chip in due fasi, ma l'azienda non ha ancora nulla per gli acquirenti che guardano al MacBook Neo di Apple.
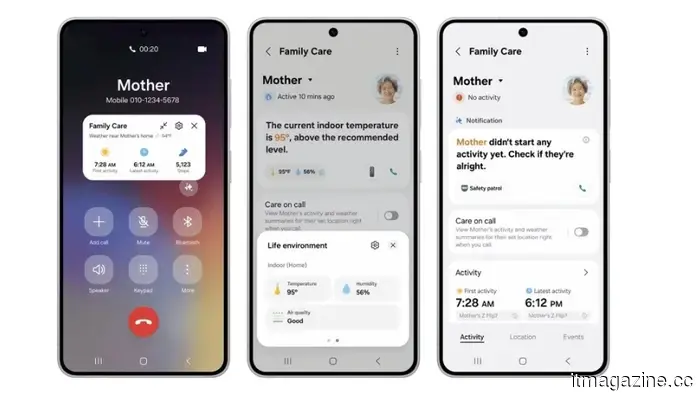 L'aggiornamento di Samsung SmartThings aggiunge il monitoraggio della cura degli anziani con rilevamento ambientale e intelligenza artificiale.
L'aggiornamento di SmartThings di Samsung utilizza aspirapolvere robot, elettrodomestici e dispositivi indossabili per monitorare i parenti anziani, rilevare cadute e declino cognitivo, e avvisare i caregiver da remoto.
L'aggiornamento di Samsung SmartThings aggiunge il monitoraggio della cura degli anziani con rilevamento ambientale e intelligenza artificiale.
L'aggiornamento di SmartThings di Samsung utilizza aspirapolvere robot, elettrodomestici e dispositivi indossabili per monitorare i parenti anziani, rilevare cadute e declino cognitivo, e avvisare i caregiver da remoto.
 Tesla punta alla Gigafactory di Shanghai per la produzione di massa del robot umanoide Optimus
Il presidente di Tesla in Cina definisce la Gigafactory di Shanghai una "chiave d'oro" per la produzione del robot Optimus, mentre lo stabilimento che costruisce metà delle auto Tesla punta alla produzione di umanoidi.
Tesla punta alla Gigafactory di Shanghai per la produzione di massa del robot umanoide Optimus
Il presidente di Tesla in Cina definisce la Gigafactory di Shanghai una "chiave d'oro" per la produzione del robot Optimus, mentre lo stabilimento che costruisce metà delle auto Tesla punta alla produzione di umanoidi.
 Tesla punta alla Gigafactory di Shanghai per la produzione di massa del robot umanoide Optimus
Il presidente di Tesla in Cina definisce la Gigafactory di Shanghai una "chiave d'oro" per la produzione del robot Optimus, mentre lo stabilimento che costruisce metà delle auto Tesla punta alla produzione di robot umanoidi.
Tesla punta alla Gigafactory di Shanghai per la produzione di massa del robot umanoide Optimus
Il presidente di Tesla in Cina definisce la Gigafactory di Shanghai una "chiave d'oro" per la produzione del robot Optimus, mentre lo stabilimento che costruisce metà delle auto Tesla punta alla produzione di robot umanoidi.
Claude Opus 4.7 guida su SWE-bench e ragionamento agentico, battendo GPT-5.4 e Gemini 3.1 Pro
Claude Opus 4.7 di Anthropic ottiene il punteggio del 64,3% su SWE-bench Pro, aggiunge coordinazione multi-agente e una risoluzione visiva 3 volte superiore, mantenendo lo stesso prezzo del suo predecessore.