
A Chinese AI lab claims it can compete with Anthropic’s extremely powerful Claude Mythos in identifying security vulnerabilities.
Security researchers claim that Z.ai's latest model can compete with Anthropic's Mythos in a significant area.
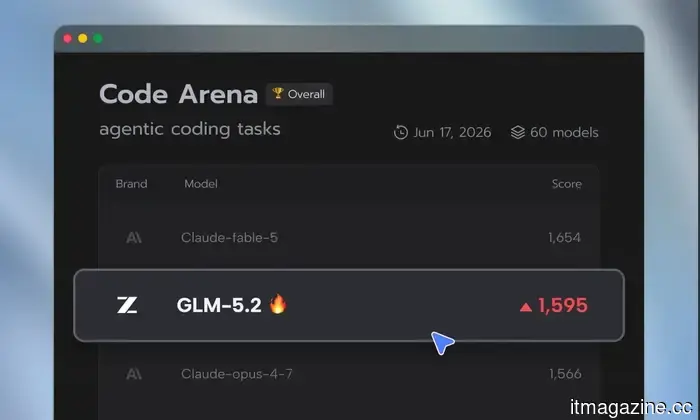
For several weeks, Anthropic’s Mythos has been regarded as the benchmark for AI-driven cybersecurity. However, that lead may be diminishing. A report from The Wall Street Journal indicates that security researchers believe Z.ai’s GLM-5.2 now matches Mythos in detecting software security vulnerabilities, although it still falls behind Anthropic and OpenAI in broader reasoning abilities.
GLM-5.2 is reducing the disparity in a crucial domain.
The report states that researchers found GLM-5.2 performs similarly to Mythos in locating software bugs, a skill that is increasingly vital as companies scramble to address vulnerabilities before they can be exploited by hackers. The model’s open-source nature allows anyone to download, modify, and utilize it on their own systems without depender on a cloud service. This adaptability makes it appealing for businesses, but it also raises concerns that cybercriminals might exploit it for malicious activities.
The report emphasizes that this does not imply that China has surpassed the U.S. in AI overall. GLM-5.2 still lags behind Anthropic and OpenAI in various general tasks. However, in the realm of cybersecurity, where even slight advancements can have significant real-world implications, the performance gap has notably decreased. According to benchmark data referenced by the Journal, GLM-5.2 has even outshone Claude Opus 4.8 in certain security tests, and researchers note that additional prompts enable it to achieve Mythos-level bug-detection capabilities.
The broader narrative isn’t about who prevails; it’s how swiftly the gap is closing.
Interestingly, this situation arises at a rather inconvenient time for the U.S. AI sector. While companies like Anthropic and OpenAI have been limiting access to their most advanced models due to national security concerns, Chinese laboratories have been moving in the opposite direction, launching increasingly sophisticated open-weight alternatives that anyone can download and utilize.
This public discourse was apparent just days ago when Elon Musk speculated that Chinese AI labs are likely to catch up to Anthropic’s premier Fable 5 by the first quarter of 2027, particularly regarding benchmark performance. Zhipu AI founder Tang Jie swiftly countered, stating it “won’t take that long.” Musk later clarified his stance, asserting that while China might match Anthropic in benchmarks by then, achieving a comparable level of “true usefulness” would be a greater challenge, crediting Anthropic’s focus on practical intelligence.
While acknowledging benchmark results is one thing, reaching true usefulness even by Q1 would be a significant accomplishment. Anthropic has wisely concentrated on enhancing useful intelligence, which may not be reflected in benchmarks but certainly impacts revenue.— Elon Musk (@elonmusk) June 18, 2026
Now, The Wall Street Journal’s recent report lends more credibility to Tang’s optimism. Rather than focusing solely on coding benchmarks, it indicates that GLM-5.2 is already on par with Anthropic’s Mythos in detecting security vulnerabilities, which is arguably one of the most crucial real-world AI applications today. This does not instantaneously position China as the frontrunner in frontier AI, but one aspect is becoming increasingly difficult to overlook: the AI race no longer offers a comfortable lead for the United States.





Other articles
 Peec AI increases its valuation to $200 million following the GEO investment.
Peec AI is said to be raising funds at a valuation of $200 million, which is double its worth from eight months prior, as it bets that GEO is emerging as the new SEO in the age of AI.
Peec AI increases its valuation to $200 million following the GEO investment.
Peec AI is said to be raising funds at a valuation of $200 million, which is double its worth from eight months prior, as it bets that GEO is emerging as the new SEO in the age of AI.
 Germany is promoting its AI implementation as a solution to its labor shortages.
Germany is presenting the rapid adoption of AI as a partial solution to its shortage of skilled workers, which amounts to hundreds of thousands annually.
Prosus profits nearly double as its investments in e-commerce and Tencent stake yield positive results.
Prosus announced approximately $7.3 billion in revenue for the year ending March 2026, with headline earnings per share increasing by 91–100% due to improved performance in e-commerce and Tencent.
Germany is promoting its AI implementation as a solution to its labor shortages.
Germany is presenting the rapid adoption of AI as a partial solution to its shortage of skilled workers, which amounts to hundreds of thousands annually.
Prosus profits nearly double as its investments in e-commerce and Tencent stake yield positive results.
Prosus announced approximately $7.3 billion in revenue for the year ending March 2026, with headline earnings per share increasing by 91–100% due to improved performance in e-commerce and Tencent.
 Amazon's quick delivery initiative has led to a loss of $15 billion for India's Eternal and Swiggy.
Eternal and Swiggy have seen a decline of over $15 billion in their market value as Amazon broadens its 'delivery in minutes' service throughout India.
Amazon's quick delivery initiative has led to a loss of $15 billion for India's Eternal and Swiggy.
Eternal and Swiggy have seen a decline of over $15 billion in their market value as Amazon broadens its 'delivery in minutes' service throughout India.
 AI chatbots may sometimes reinforce your misconceptions. Researchers suggest that you should watch for three indicators.
Researchers have suggested a new framework that explains how AI chatbots can strengthen delusional thoughts, emphasizing three behaviors that could lead to an "amplification spiral."
AI chatbots may sometimes reinforce your misconceptions. Researchers suggest that you should watch for three indicators.
Researchers have suggested a new framework that explains how AI chatbots can strengthen delusional thoughts, emphasizing three behaviors that could lead to an "amplification spiral."
 Trump warns of imposing 100% tariffs in response to digital services taxes.
Trump warns of imposing a 100% tariff on any nation that enacts digital services taxes targeting US tech companies, just a day after the EU finalized a trade agreement. Brussels remains steadfast.
Trump warns of imposing 100% tariffs in response to digital services taxes.
Trump warns of imposing a 100% tariff on any nation that enacts digital services taxes targeting US tech companies, just a day after the EU finalized a trade agreement. Brussels remains steadfast.
A Chinese AI lab claims it can compete with Anthropic’s extremely powerful Claude Mythos in identifying security vulnerabilities.
The Wall Street Journal has reported that China's GLM-5.2 AI model is capable of competing with Anthropic's Mythos in cybersecurity functions, indicating a swiftly decreasing disparity in AI technology.