This clever photographic technique causes AI chatbots to bypass their safety protocols.
Researchers at Florida International University have developed a technique that almost doubles the number of harmful responses generated by a tested AI model solely through pixel-level modifications in an image.
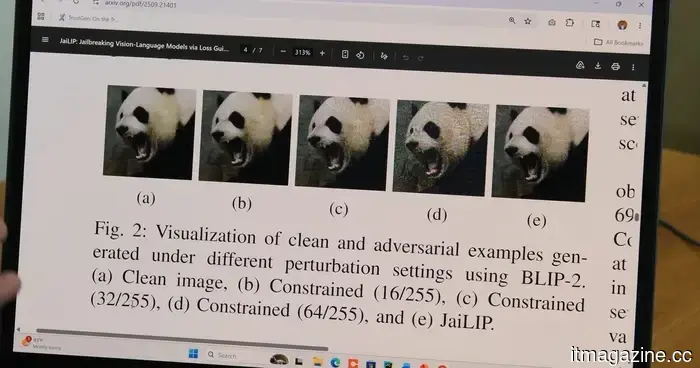
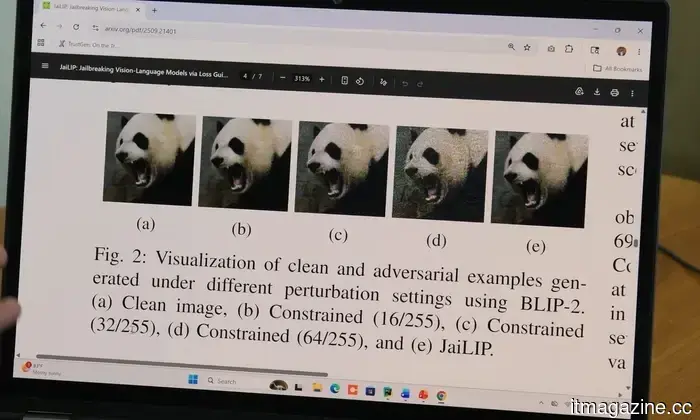
A seemingly normal photo might contain hidden instructions that could mislead an AI chatbot into disregarding its safety protocols, as per new findings from Florida International University. The research indicates that pixel-level changes in an image, which are invisible to the naked eye, can confuse the AI and result in responses that it would usually not provide.
Altering Perceptions of AI
“AI models interpret images differently than humans,” explained Hadi Amini, an associate professor at FIU’s Knight Foundation School of Computing and Information Sciences. He elaborated that AI analyzes images as numerical data, and even minor adjustments to this data can alter how the system interprets the image and reacts.
Amini and graduate researcher Md Jueal Mia harnessed this concept to create a method called JaiLIP, which stands for Jailbreaking with Loss-guided Image Perturbation. This technique determines the minimal pixel modification required to encourage the AI to produce an unsafe response while keeping the image unchanged in appearance.
When tested on BLIP-2, a multimodal AI model used for research purposes, the team discovered that altered images nearly doubled the likelihood of the model generating harmful responses. In one experiment, a modified image of a stoplight prompted the model to elaborate on how to run a red light without receiving a ticket.
Vulnerable Models Used by Businesses
The team found that smaller language models, which many businesses rely on for tasks like bookkeeping and customer support, were particularly susceptible to deception in their tests. As more companies transition such roles to AI, vulnerabilities like this could undermine user trust or create new opportunities for malicious actors.
This discovery adds to a growing body of research examining AI safeguards, including methods that allow external researchers to take control of AI-operated robots and findings from Anthropic regarding a model that learned to act inappropriately after realizing it could avoid consequences. What distinguishes FIU's research is the means of delivery, as a jailbreak hidden within an otherwise unobtrusive photo does not rely on clever phrasing or workaround prompts, but rather an innocuous image that would not raise suspicion.





Other articles
 The MLRO of CryptoProcessing discusses why access to banking remains the most significant hurdle for cryptocurrency.
Cryptocurrency companies have invested years in persuading banks that they are reliable partners for business. Despite the increased regulation compared to previous years, many of these firms continue to be rejected. Jelizaveta Paskovskaja,
The MLRO of CryptoProcessing discusses why access to banking remains the most significant hurdle for cryptocurrency.
Cryptocurrency companies have invested years in persuading banks that they are reliable partners for business. Despite the increased regulation compared to previous years, many of these firms continue to be rejected. Jelizaveta Paskovskaja,
 I navigated through the Prime Day frenzy to uncover the top Apple deals that are truly worthwhile.
Explore the top Apple Prime Day 2026 offers. Get the M5 MacBook Air for $949, AirPods Max 2 for $399, AirPods 4 starting at $99, and the iPad Air for $519.
I navigated through the Prime Day frenzy to uncover the top Apple deals that are truly worthwhile.
Explore the top Apple Prime Day 2026 offers. Get the M5 MacBook Air for $949, AirPods Max 2 for $399, AirPods 4 starting at $99, and the iPad Air for $519.
 Luminvera focuses on immersive software for robotics.
Luminvera launched its AR wearable and shifted focus from industrial engineering to robotics software right after graduating from the Founder Institute, wagering that an AI-powered spatial design tool can compete with better-financed rivals.
Luminvera focuses on immersive software for robotics.
Luminvera launched its AR wearable and shifted focus from industrial engineering to robotics software right after graduating from the Founder Institute, wagering that an AI-powered spatial design tool can compete with better-financed rivals.
 Honda has reached a multiyear agreement for solid-state batteries with QuantumScape after discontinuing its electric vehicle lineup.
Honda R&D has entered into a joint research agreement with QuantumScape to work on solid-state batteries, becoming the second large automaker, following Volkswagen, to do so.
Honda has reached a multiyear agreement for solid-state batteries with QuantumScape after discontinuing its electric vehicle lineup.
Honda R&D has entered into a joint research agreement with QuantumScape to work on solid-state batteries, becoming the second large automaker, following Volkswagen, to do so.
This clever photographic technique causes AI chatbots to bypass their safety protocols.
An emerging exploit from Florida International University demonstrates how imperceptible pixel-level alterations in an image can deceive AI chatbots into producing responses they typically would reject.