The significance of data quality in large-scale data operations.
Data quality has often been considered an afterthought. Teams invest months in implementing a feature, constructing pipelines, and creating dashboards, only to question the accuracy of the underlying data when a stakeholder raises concerns about an unusual number. By that stage, the cost of addressing the issue has significantly increased.
This is a widespread issue, affecting engineering teams of all sizes, with repercussions ranging from wasted computing resources to a complete loss of trust from leadership in the data team. Many of these failures could be avoided if data quality were prioritized from the very beginning, rather than treated as a task to tackle later.
A typical data project usually starts with a cross-departmental conversation about a new feature and the metrics stakeholders wish to monitor. The data team collaborates with data scientists and analysts to establish key metrics, while engineering assesses what can realistically be instrumented and identifies constraints. A data engineer then converts this information into a logging specification that outlines the specific events to track, the fields to include, and the significance of each.
This logging specification serves as a contract that everyone refers to, and downstream users depend on it. When everything functions as planned, the entire system operates smoothly.
Before data is deployed in production, there generally is a validation process in development and staging environments. Engineers review key interaction flows, verify that the correct events are triggered with the appropriate fields, correct any errors, and continue this cycle until everything is approved. This process is time-consuming, but it is intended to act as a safety net.
The problem arises after this phase.
The difference between staging and production realities
Once the data is live and the ETL pipelines are operational, most teams operate under the assumption that the data contract established during instrumentation will remain intact. However, this is rarely the case in the long term.
Consider a common scenario: your pipeline anticipates an event to trigger when a user completes a certain action. Months later, a server-side change adjusts the timing, causing the event to trigger earlier in the process with a different field value. No one identifies this as a data-affecting change. The pipeline continues to function, and the metrics keep appearing on dashboards.
Weeks or months may pass before anyone realizes that the metrics appear stagnant. A data scientist investigates, traces the issue back, and identifies the root cause. The team must then undertake a comprehensive remediation effort: updating ETL logic, backfilling affected partitions across aggregated tables and reports, and having an uncomfortable discussion with stakeholders regarding how long the numbers have been inaccurate.
The cumulative cost of that single overlooked change includes engineering time for analysis, efforts for codebase updates, resources for backfills, and, most critically, a loss of trust in the data team. Once stakeholders experience unreliable numbers several times, they begin to doubt everything. Rebuilding that confidence is challenging.
This pattern is particularly prevalent in large systems that contain numerous independent microservices, each evolving on its own release schedule. There is no single point of failure, only a gradual divergence between what the pipeline anticipates and what the data truly consists of.
Why validation cannot conclude at staging
The fundamental issue is that data validation is often regarded as a one-time check rather than a continuous process. Staging validation is crucial, but it only verifies the system's state at a specific moment. Production is constantly evolving.
What is required is the enforcement of data quality at every level of the pipeline, from when data is generated, through transport, and all the way to the processed tables that consumers rely upon. The current data tooling ecosystem has advanced sufficiently to make this feasible.
Ensuring quality at the source
The first line of defense is the data contract established at the producer level. Enforcing a strict schema at the point of emission with typed fields and defined structures means that a breaking change will fail immediately instead of silently cascading downstream. Schema registries, often used with streaming platforms like Apache Kafka, serialize data against a schema before transportation and validate it once more upon deserialization. Compatibility checks ensure that schema evolution does not inadvertently disrupt downstream pipelines.
Using Avro formatted schemas stored in a schema registry has become a standard practice for this reason. They establish an explicit, versioned contract between producers and consumers, enforced at runtime rather than simply documented in a specification file that may or may not be consulted.
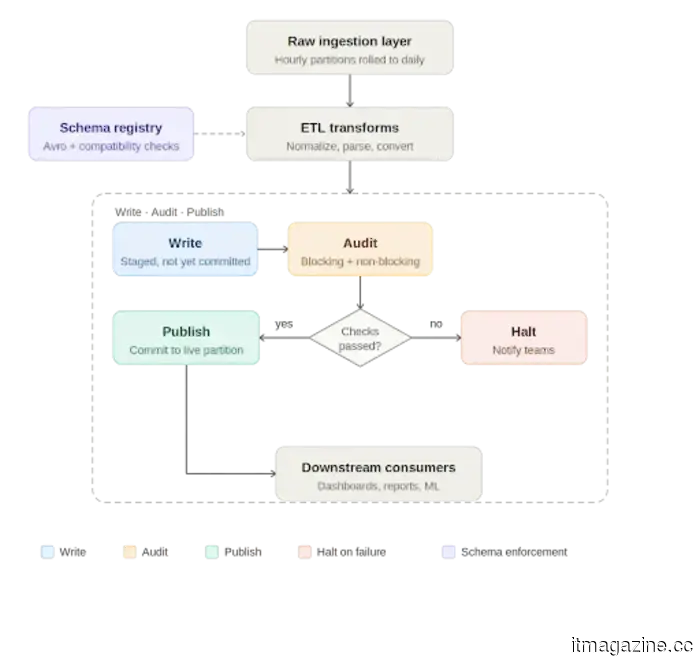
Write, audit, publish: A quality gate in the pipeline
At the processing level, Apache Iceberg has introduced a practical pattern for enforcing data quality called Write-Audit-Publish (WAP). Iceberg uses a file metadata model where every write is tracked as a commit. The WAP workflow takes advantage of this by adding an audit step before declaring data production-ready.
In practice, the daily pipeline functions as follows: raw data arrives in an ingestion layer, usually aggregated from smaller time window partitions into a full daily partition. The ETL job processes this data, applying transformations like normalizations, timezone adjustments, and default value handling, before writing to an Iceberg table. If WAP is active on
Other articles
 I was quite critical of the Galaxy S26 in my review, yet it remains frustratingly easy to appreciate.
I still believe the Galaxy S26 is too cautious for a flagship device, but I can't overlook how enjoyable it is to use.
I was quite critical of the Galaxy S26 in my review, yet it remains frustratingly easy to appreciate.
I still believe the Galaxy S26 is too cautious for a flagship device, but I can't overlook how enjoyable it is to use.
 The importance of data quality when handling data on a large scale.
Discover the importance of data quality for contemporary data pipelines, the necessity for validation to go beyond just staging, and the methods to create dependable systems at scale.
The importance of data quality when handling data on a large scale.
Discover the importance of data quality for contemporary data pipelines, the necessity for validation to go beyond just staging, and the methods to create dependable systems at scale.
 While the PlayStation 6 may not cause a significant price surprise, it's best not to get too carried away with the optimistic chatter.
Initial reports indicate that the PS6 could be released at a price similar to that of the PS5, even with the increasing costs of memory and chips.
While the PlayStation 6 may not cause a significant price surprise, it's best not to get too carried away with the optimistic chatter.
Initial reports indicate that the PS6 could be released at a price similar to that of the PS5, even with the increasing costs of memory and chips.
 X prepares to launch a dedicated messaging app as XChat becomes available on the App Store.
The XChat will provide end-to-end encrypted messaging and will be accessible to iPhone users on April 17, featuring support for more than 45 languages.
X prepares to launch a dedicated messaging app as XChat becomes available on the App Store.
The XChat will provide end-to-end encrypted messaging and will be accessible to iPhone users on April 17, featuring support for more than 45 languages.
 Anthropic integrates Claude into Microsoft Word, with legal contract review being the primary application.
Anthropic's Claude for Word beta has been launched in Microsoft Word for Team and Enterprise users, with its initial application focused on reviewing legal contracts.
Anthropic integrates Claude into Microsoft Word, with legal contract review being the primary application.
Anthropic's Claude for Word beta has been launched in Microsoft Word for Team and Enterprise users, with its initial application focused on reviewing legal contracts.
The significance of data quality in large-scale data operations.
Discover the importance of data quality for contemporary data pipelines, the necessity for validation to go beyond just staging, and strategies for constructing dependable systems at scale.