The importance of data quality when handling data on a large scale.
Data quality has historically been overlooked. Teams often invest months in developing features, constructing pipelines, and creating dashboards, only to question the accuracy of the underlying data when a stakeholder points out an unusual figure. By that time, the expense of rectifying the issues has significantly increased.
This is not an isolated issue; it is prevalent across engineering organizations of all sizes, leading to consequences that range from wasted computational resources to a complete loss of trust in the data team by leadership. Most of these problems can be avoided if data quality is prioritized from the very beginning instead of being treated as a task for later remediation.
How a typical data project begins
To understand the issue, it’s useful to examine how most data engineering projects commence. It typically starts with a cross-functional discussion about the launch of a new feature and the metrics stakeholders wish to track. The data team collaborates with data scientists and analysts to identify key metrics. Engineering assesses what can be effectively instrumented and identifies various constraints. A data engineer then drafts a logging specification outlining the events to capture, the fields to include, and the significance of each field.
This logging specification serves as the reference point for everyone involved. Downstream users depend on it. When functioning correctly, the entire system operates smoothly.
Before data is deployed to production, there is usually a validation stage within development and staging environments. Engineers review key interaction flows, ensure the appropriate events are triggered with the correct fields, address any issues, and repeat the process until everything is validated. Although this is time-consuming, it is intended to serve as a safety net.
The challenge arises after this phase.
The disconnect between staging and production
Once data is live and the ETL pipelines are operational, most teams operate under the unspoken assumption that the data contract agreed upon during instrumentation will remain intact. However, this is rarely the case in the long term.
Consider a frequent scenario: your pipeline is designed to trigger an event when a user completes a particular action. Months later, a server-side adjustment alters the timing, leading to the event firing earlier with a different value in a crucial field. No one identifies this as a data-affecting change, so the pipeline continues to operate, and the metrics keep flowing into dashboards.
Weeks or even months may elapse before someone realizes the metrics appear stagnant. A data scientist investigates, traces the issue back, and identifies the root cause. The team now faces a comprehensive remediation effort: revising the ETL logic, backfilling affected partitions across aggregated tables and reporting layers, and engaging in uncomfortable discussions with stakeholders about the duration in which the metrics have been inaccurate.
The cumulative cost of that single overlooked change encompasses analysis time, codebase updates, computational resources for backfills, and most damagingly, a loss of trust in the data team. After stakeholders have been misled by inaccurate numbers a few times, they begin to question everything. Rebuilding that lost confidence is a difficult task.
This pattern is particularly common in large systems comprising numerous independent microservices, each evolving independently on its release schedule. There isn’t a single point of failure, but rather a gradual divergence between expectations of the pipeline and the actual data.
Why validation must extend beyond staging
The fundamental issue lies in treating data validation as a singular gate instead of an ongoing process. Staging validation is vital, but it only confirms the system's condition at a specific moment. In production, conditions are constantly changing.
What is necessary is data quality enforcement at each level of the pipeline, from the moment data is produced, through its transport, and right into the processed tables that consumers rely on. The modern data tooling ecosystem has advanced sufficiently to make this feasible.
Enforcing quality at the source
The initial line of defense is the data contract at the producer level. Enforcing a strict schema at the emission point with typed fields and defined structure ensures that any breaking changes are identified immediately rather than being quietly propagated downstream. Schema registries, often used with streaming platforms like Apache Kafka, serialize data against a schema prior to transport and validate it again upon deserialization. Compatibility checks guarantee that schema evolution does not inadvertently disrupt consuming pipelines.
Avro formatted schemas stored in a schema registry are a commonly adopted approach for this reason. They establish an explicit, versioned contract between producers and consumers that is enforced at runtime, rather than merely documented in a specification that may or may not be reviewed.
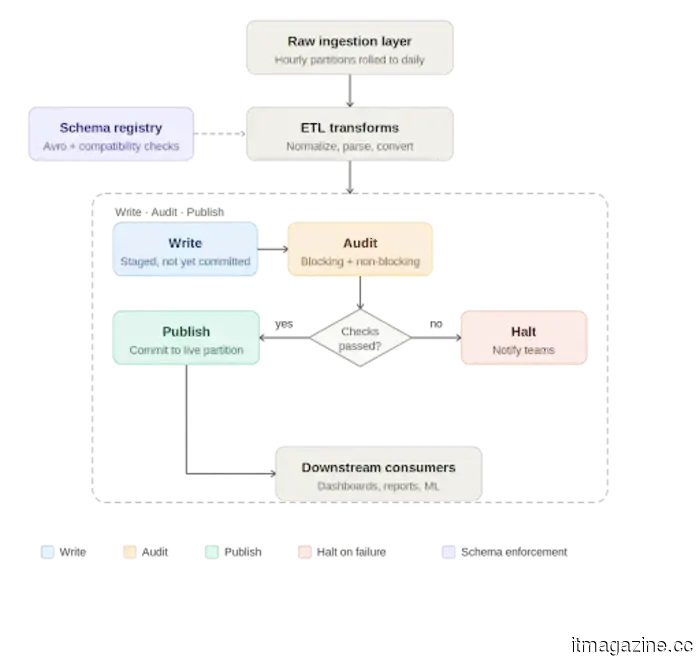
Write, audit, publish: A quality checkpoint in the pipeline
At the processing level, Apache Iceberg has introduced a beneficial method for enforcing data quality known as Write-Audit-Publish, or WAP. Iceberg utilizes a file metadata model where every write is documented as a commit. The WAP process leverages this to incorporate an audit step before data is deemed production-ready.
In practical terms, the daily pipeline operates as follows: Raw data enters an ingestion layer, usually aggregated from smaller time window partitions into a complete daily partition. The ETL job then processes this data, conducting transformations
Other articles
 I criticized the Galaxy S26 in my review, yet it remains frustratingly easy to appreciate.
I still believe that the Galaxy S26 is too cautious for a flagship price — however, I can't overlook how enjoyable it is to use.
I criticized the Galaxy S26 in my review, yet it remains frustratingly easy to appreciate.
I still believe that the Galaxy S26 is too cautious for a flagship price — however, I can't overlook how enjoyable it is to use.
 Microsoft Teams is set to address an incredibly frustrating daily issue in meetings.
Microsoft is introducing a pre-join microphone test for Teams, along with the launch of privacy-focused Copilot recaps. This update will provide regular users with a more seamless beginning to their calls and offer businesses enhanced oversight over AI-generated meeting summaries.
Microsoft Teams is set to address an incredibly frustrating daily issue in meetings.
Microsoft is introducing a pre-join microphone test for Teams, along with the launch of privacy-focused Copilot recaps. This update will provide regular users with a more seamless beginning to their calls and offer businesses enhanced oversight over AI-generated meeting summaries.
 The significance of data quality in large-scale data operations.
Discover the importance of data quality for contemporary data pipelines, the necessity for validation to go beyond just staging, and strategies for constructing dependable systems at scale.
The significance of data quality in large-scale data operations.
Discover the importance of data quality for contemporary data pipelines, the necessity for validation to go beyond just staging, and strategies for constructing dependable systems at scale.
 In case you didn't notice, the price of YouTube Music Premium has also increased.
YouTube has increased the prices of its Premium and Music subscriptions, contributing to the rising expenses across various streaming services.
In case you didn't notice, the price of YouTube Music Premium has also increased.
YouTube has increased the prices of its Premium and Music subscriptions, contributing to the rising expenses across various streaming services.
 Anthropic integrates Claude into Microsoft Word, with legal contract review being its primary application.
Anthropic's Claude for Word beta is now available in Microsoft Word for Team and Enterprise users, with the initial use case focused on legal contract review.
Anthropic integrates Claude into Microsoft Word, with legal contract review being its primary application.
Anthropic's Claude for Word beta is now available in Microsoft Word for Team and Enterprise users, with the initial use case focused on legal contract review.
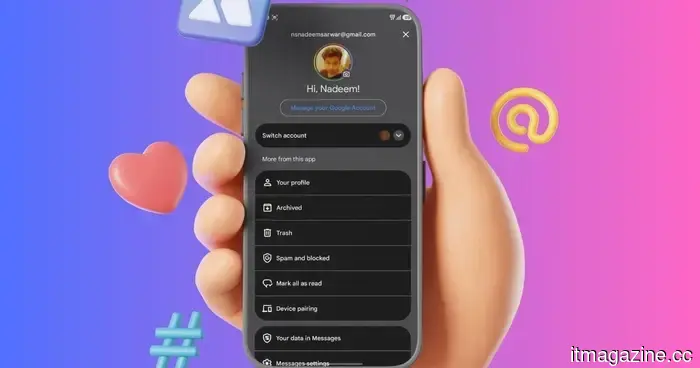 Google Messages now includes a Trash folder for your less important conversations to linger in.
Google Messages has introduced a Trash folder that allows deleted conversations to be recovered within a 30-day period before they are permanently erased.
Google Messages now includes a Trash folder for your less important conversations to linger in.
Google Messages has introduced a Trash folder that allows deleted conversations to be recovered within a 30-day period before they are permanently erased.
The importance of data quality when handling data on a large scale.
Discover the importance of data quality for contemporary data pipelines, the necessity for validation to go beyond just staging, and the methods to create dependable systems at scale.