
Google has introduced Gemma 4.
Based on the same research as Gemini 3, the new family includes a 2B edge model that operates on a Raspberry Pi and a 31B dense model, which is currently the third-ranked model on the Arena AI open-model leaderboard. The shift to an Apache 2.0 license marks a significant change from earlier Gemma releases.
Google has introduced Gemma 4, the latest version of its open-weight model family, available in four sizes tailored for various applications, from on-device inference on smartphones to workstation-class settings.
These models leverage the same research and technology that form the foundation of Gemini 3, Google’s proprietary frontier model, and are now released under an Apache 2.0 license, which offers more permissive terms compared to earlier Gemma versions. Hugging Face co-founder Clément Delangue referred to this change as “a huge milestone.”
Demis Hassabis, CEO of Google DeepMind, described these new models as “the best open models in the world for their respective sizes.”
The four variants include the Effective 2B (E2B) and Effective 4B (E4B) edge models, optimized for on-device use on smartphones, Raspberry Pi, and Jetson Nano hardware, developed in partnership with the Pixel team, Qualcomm, and MediaTek. Additionally, the 26B Mixture-of-Experts (MoE) and 31B Dense models are designed for offline use on developer hardware and consumer GPUs.
Currently, the 31B Dense model ranks third among all open models on the Arena AI text leaderboard, while the 26B MoE is in sixth place. Google asserts that both larger models outperform competitors that are up to 20 times their size according to this benchmark.
The unquantized weights of the 31B model can fit on a single 80GB Nvidia H100 GPU, while quantized versions are compatible with consumer hardware.
All four models feature multimodal capabilities, enabling them to process video and images natively and have been trained in over 140 languages. The E2B and E4B models also support native audio input for speech recognition. The context windows are 128K tokens for the edge models and 256K for the larger variants.
Google emphasizes improvements in multi-step reasoning, native function-calling, and structured JSON output for agentic workflows, alongside offline code generation capabilities. In terms of performance, the Android Developers Blog indicates that the E2B model runs three times faster than the E4B, while the entire edge family is up to four times faster than previous Gemma versions and consumes up to 60% less battery.
The E2B and E4B models serve as the foundation for Gemini Nano 4, Google’s next-generation on-device model for Android, which is set to be released on consumer devices later this year.
Since its initial launch, Gemma has garnered over 400 million downloads and over 100,000 community-generated variants, figures that Google cites as proof of extensive developer adoption.
Gemma 4 is now available on Hugging Face, Kaggle, and Ollama, with the 31B and 26B models accessible through Google AI Studio and the edge models via AI Edge Gallery.
The decision to adopt Apache 2.0 licensing represents the most significant commercial signal of the launch: it eliminates restrictions that had hindered certain enterprise and commercial deployments under prior Gemma terms, thus broadening the ecosystem to accommodate a wider array of production use cases.
Other articles
 This novel AI attack extracts models without interacting with the system.
AI models might no longer be secure within protected environments, as researchers demonstrate that signals from GPUs can disclose their internal architecture without the need for hacking, utilizing a small antenna and side-channel analysis from a distance of several meters.
This novel AI attack extracts models without interacting with the system.
AI models might no longer be secure within protected environments, as researchers demonstrate that signals from GPUs can disclose their internal architecture without the need for hacking, utilizing a small antenna and side-channel analysis from a distance of several meters.
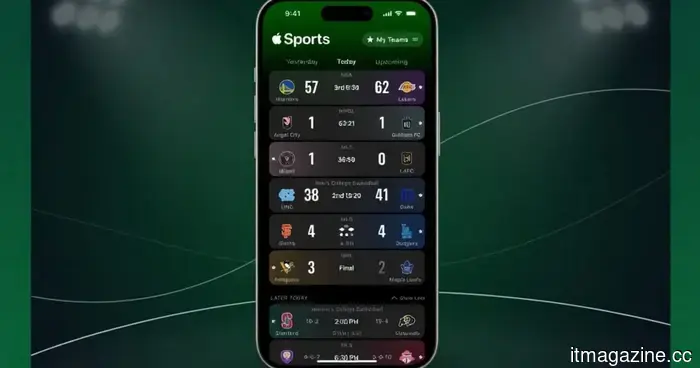 Follow your World Cup teams directly on your iPhone with this Apple Sports update.
Apple Sports introduces World Cup support, enabling you to monitor teams, scores, and matches in real time with updates on your lock screen. Here's how this new feature alters your experience of following the 2026 tournament.
Follow your World Cup teams directly on your iPhone with this Apple Sports update.
Apple Sports introduces World Cup support, enabling you to monitor teams, scores, and matches in real time with updates on your lock screen. Here's how this new feature alters your experience of following the 2026 tournament.
 Samsung is finally introducing much-awaited Google Cast support to its older television models.
Samsung is finally responding to a long-awaited demand from its users: Google Cast support is being introduced not only to its new TVs but also to certain older models. This highly sought-after feature will be available for selected 2023 and 2024 models. It may also be extended to Smart Monitors and other recently released Tizen OS devices. The rollout has begun [...]
Samsung is finally introducing much-awaited Google Cast support to its older television models.
Samsung is finally responding to a long-awaited demand from its users: Google Cast support is being introduced not only to its new TVs but also to certain older models. This highly sought-after feature will be available for selected 2023 and 2024 models. It may also be extended to Smart Monitors and other recently released Tizen OS devices. The rollout has begun [...]
 This unconventional MacBook Neo water-cooling modification enhances its performance significantly.
A tailored liquid-cooling modification enabled the MacBook Neo to operate much cooler and improved performance enough to surpass the M1 MacBook Air in benchmark tests.
This unconventional MacBook Neo water-cooling modification enhances its performance significantly.
A tailored liquid-cooling modification enabled the MacBook Neo to operate much cooler and improved performance enough to surpass the M1 MacBook Air in benchmark tests.
 The UK government is addressing the issues surrounding subscription services, and it’s time for the US to follow suit.
The UK government is taking action against subscription traps by introducing new regulations that simplify cancellations, clarify trial terms, and have the potential to save consumers as much as £170 annually.
The UK government is addressing the issues surrounding subscription services, and it’s time for the US to follow suit.
The UK government is taking action against subscription traps by introducing new regulations that simplify cancellations, clarify trial terms, and have the potential to save consumers as much as £170 annually.
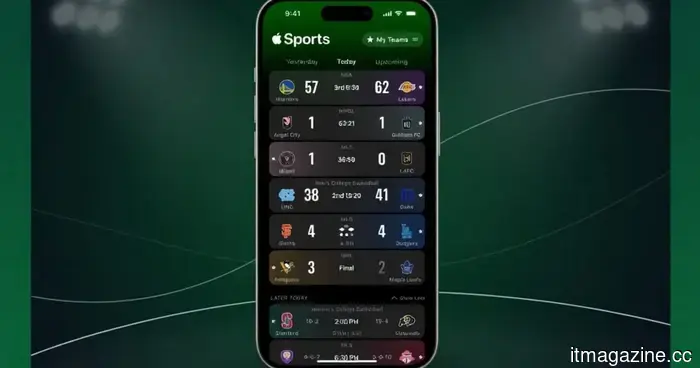 Follow your World Cup teams directly on your iPhone with this Apple Sports update.
Apple Sports introduces World Cup support, allowing you to monitor teams, scores, and matches in real time with updates on your lock screen. Here’s how this new feature alters your experience of the 2026 tournament.
Follow your World Cup teams directly on your iPhone with this Apple Sports update.
Apple Sports introduces World Cup support, allowing you to monitor teams, scores, and matches in real time with updates on your lock screen. Here’s how this new feature alters your experience of the 2026 tournament.
Google has introduced Gemma 4.
Google has introduced Gemma 4, which includes four open-weight models ranging from E2B edge to 31B Dense, developed based on Gemini 3 research and released under the Apache 2.0 license.