Perché il prossimo salto nell'IA video è insegnare agli avatar a vedere e ascoltare
TL;DRAI video si sta spostando da una corsa alla fedeltà a una corsa all'interattività. Una nuova classe di modelli di avatar interattivi può essere valutata su tre livelli: Livello 1 (parlare), Livello 2 (parlare e ascoltare) e Livello 3 (parlare, ascoltare e vedere). Il salto dal Livello 1 al Livello 2, dove un avatar impara ad ascoltare e reagire in tempo reale, è la svolta che trasforma un volto parlante in un convincente interlocutore conversazionale.
Negli ultimi anni, i progressi nei video generativi e negli avatar AI sono stati misurati quasi interamente in fedeltà, con ogni nuovo modello che fa progressi significativi nel fornire dettagli più nitidi, fisica migliore e movimenti più fluidi confezionati in clip più lunghe. Quella corsa è tutt'altro che finita, ma sta iniziando a perdere una direzione più interessante. Il video, come formato di media online, si sta evolvendo da un'esperienza statica e simile a una trasmissione a una più interattiva.
Il software è sempre più mediato da agenti piuttosto che da pulsanti e menu, e per quasi qualsiasi flusso di lavoro tu possa nominare, qualcuno sta costruendo un agente per gestirlo. In parallelo, architetture ibride che mescolano metodi autoregressivi e di diffusione sono diventate una delle aree più vivaci della ricerca video. E un numero crescente di team sta trattando il video interattivo come una base per classi di applicazioni completamente nuove, dalla simulazione di mondi aperti al dialogo dal vivo. Mettendo tutto insieme, la conclusione è piuttosto chiara: l'interattività, non la risoluzione, sta diventando la frontiera.
Di conseguenza, sta emergendo una nuova categoria di modelli video il cui compito è produrre un agente parlante che reagisce a un umano in tempo reale, con latenze abbastanza basse da sostenere una conversazione naturale, di solito sotto un secondo. Similmente a come le auto a guida autonoma sono definite da sei livelli di automazione, questi Modelli di Avatar Interattivi si presentano in tre livelli di interattività definiti dalle loro capacità tecniche.
Il 💜 della tecnologia UE Gli ultimi rumori dalla scena tecnologica dell'UE, una storia dal nostro saggio fondatore Boris e alcune opere d'arte AI discutibili. È gratuito, ogni settimana, nella tua casella di posta. Iscriviti ora! Un sistema di Livello 1 può parlare. È guidato interamente dal proprio audio e non ha consapevolezza della persona di fronte a esso. Quasi ogni sistema di avatar parlanti disponibile oggi raggiunge questo livello di prestazioni. È un problema di generazione unidirezionale: dato il parlato, produce un volto parlante plausibile.
Un sistema di Livello 2 può parlare e ascoltare. Riceve l'audio dell'utente così come il proprio e reagisce mentre l'altra persona sta parlando. Queste reazioni includono piccoli segnali visivi che i veri ascoltatori producono, come un cenno di approvazione o un cambiamento di espressione, e con segnali vocali come un breve "mhm" per mostrare riconoscimento. Questo è un problema fondamentalmente più difficile rispetto al Livello 1, perché il modello non sta più generando in isolamento. Deve interpretare un segnale in arrivo e rispondere ad esso continuamente, in tempo.
Un sistema di Livello 3 può parlare, ascoltare e vedere. Oltre all'audio, prende il feed della telecamera dell'utente, in modo da poter rispondere alla postura, al gesto e all'espressione facciale proprio come le persone si adattano l'una all'altra durante una videochiamata.
Il motivo per cui vogliamo evolvere oltre i modelli di Livello 1 è che un avatar che parla senza alcuna consapevolezza della persona con cui sta parlando appare vivo senza essere reattivo. Si muove mentre parli, spesso in modi che non hanno nulla a che fare con ciò che stai dicendo, e l'effetto è sorprendente o inquietante. Rispetto ai sistemi conversazionali solo audio, che almeno rimangono silenziosi e attenti mentre parli, un avatar che non ascolta può a volte sembrare peggiore di nessun avatar.
Ecco perché il salto dal Livello 1 al Livello 2 è quello che conta di più. Far ascoltare un avatar in modo convincente è ciò che trasforma un volto parlante in qualcosa che sembra un interlocutore. Raggiungere questo obiettivo è più difficile di quanto sembri, perché ascoltare non è puramente visivo. Il lato vocale, il tempismo di un'interruzione, la prosodia di un riconoscimento, la pausa di mezzo secondo prima di una reazione portano tanto senso di coinvolgimento quanto il cenno di assenso. L'approccio ingenuo è quello di montare un sistema vocale conversazionale su un modello video in uno stack. Il percorso più promettente è modellare audio e movimento congiuntamente, apprendendo come voce e movimento si plasmano a vicenda in tempo reale. La lezione dei recenti modelli video multimodali è che prevedere entrambe le modalità insieme è spesso dove il realismo supera una soglia piuttosto che avanzare lentamente.
I modelli di avatar di Livello 3 possono utilizzare il feed video dalla telecamera di una persona per creare l'esperienza conversazionale definitiva che replica perfettamente una videochiamata. Ad esempio, immagina di parlare con qualcuno; se si alzano e se ne vanno, naturalmente smetti di parlare perché è un chiaro segnale che la conversazione è finita. Pertanto, gli avatar interattivi di Livello 3 non solo reagiscono alle emozioni o al tono di voce di una persona, ma anche a ciò che l'utente sta facendo. Di conseguenza, possono modellare completamente le interazioni umane.
Costruire verso il Livello 3 è uno dei problemi più ambiziosi nella ricerca video applicata, e arrivarci richiederà un lavoro sostenuto e cumulativo su dati, modelli e ingegneria dei sistemi, qualcosa in cui Synthesia ha un eccellente curriculum.
Altri articoli
 Tesla ha consegnato 480.126 veicoli nel secondo trimestre, superando di gran lunga i 406.000 previsti da Wall Street.
Tesla ha superato le stime di consegna del 18% nel secondo trimestre del 2026, registrando 480.126 consegne. Si è trattato di un aumento del 25% su base annua e di un balzo del 34% rispetto al primo trimestre mentre l'azienda cerca di riprendersi.
Tesla ha consegnato 480.126 veicoli nel secondo trimestre, superando di gran lunga i 406.000 previsti da Wall Street.
Tesla ha superato le stime di consegna del 18% nel secondo trimestre del 2026, registrando 480.126 consegne. Si è trattato di un aumento del 25% su base annua e di un balzo del 34% rispetto al primo trimestre mentre l'azienda cerca di riprendersi.
 Google perde l'ultimo appello contro la storica multa di 4,1 miliardi di euro dell'UE per Android
La Corte di Giustizia dell'UE ha respinto l'ultimo ricorso di Google contro una multa antitrust di 4,1 miliardi di euro per Android, chiudendo un caso di otto anni.
Google perde l'ultimo appello contro la storica multa di 4,1 miliardi di euro dell'UE per Android
La Corte di Giustizia dell'UE ha respinto l'ultimo ricorso di Google contro una multa antitrust di 4,1 miliardi di euro per Android, chiudendo un caso di otto anni.
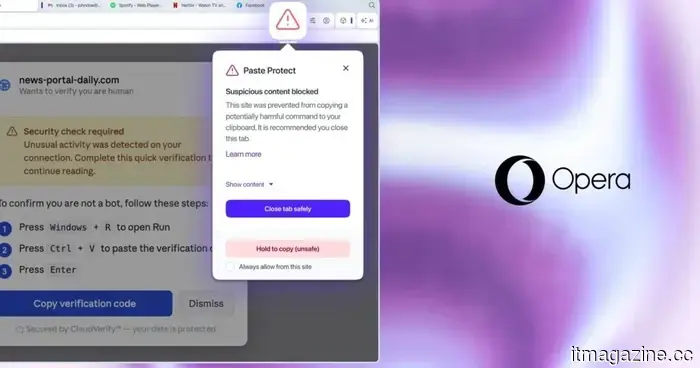 La nuova funzione Paste Protect di Opera ferma l'attacco agli appunti che il tuo antivirus non riesce a rilevare.
La nuova funzione Paste Protect di Opera blocca nativamente gli attacchi ClickFix nel suo browser desktop, rendendolo il primo grande browser a affrontare una minaccia che il software antivirus non è progettato per rilevare.
La nuova funzione Paste Protect di Opera ferma l'attacco agli appunti che il tuo antivirus non riesce a rilevare.
La nuova funzione Paste Protect di Opera blocca nativamente gli attacchi ClickFix nel suo browser desktop, rendendolo il primo grande browser a affrontare una minaccia che il software antivirus non è progettato per rilevare.
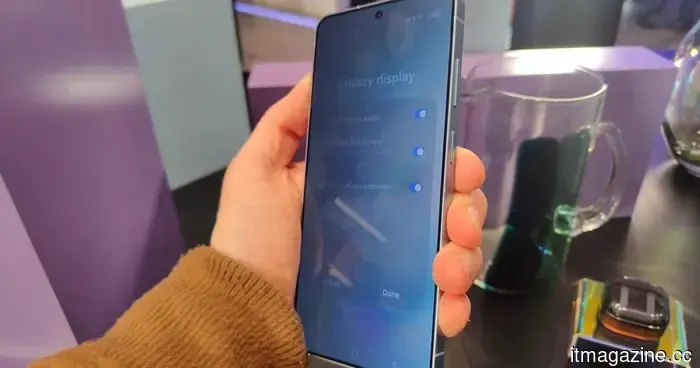 Samsung potrebbe smettere di limitare il display anti-spionaggio del Galaxy S26 Ultra con la serie Galaxy S27.
Nuova fuga di notizie afferma che Samsung potrebbe portare la sua tecnologia di display privacy Flex Magic Pixel all'intera gamma Galaxy S27, inclusi i modelli base, Plus, Pro e Ultra.
Samsung potrebbe smettere di limitare il display anti-spionaggio del Galaxy S26 Ultra con la serie Galaxy S27.
Nuova fuga di notizie afferma che Samsung potrebbe portare la sua tecnologia di display privacy Flex Magic Pixel all'intera gamma Galaxy S27, inclusi i modelli base, Plus, Pro e Ultra.
 Le vendite di Ford negli Stati Uniti nel secondo trimestre sono diminuite del 10,3% poiché le vendite di veicoli elettrici sono scese del 40,7% e una carenza di alluminio ha colpito i camion della serie F.
Ford ha venduto 549.200 veicoli nel secondo trimestre, in calo del 10,3%. Le vendite di veicoli elettrici puri sono crollate del 40,7%. Le vendite della serie F sono diminuite dell'11% dopo che il suo principale fornitore di alluminio ha subito due incendi in fabbrica.
Le vendite di Ford negli Stati Uniti nel secondo trimestre sono diminuite del 10,3% poiché le vendite di veicoli elettrici sono scese del 40,7% e una carenza di alluminio ha colpito i camion della serie F.
Ford ha venduto 549.200 veicoli nel secondo trimestre, in calo del 10,3%. Le vendite di veicoli elettrici puri sono crollate del 40,7%. Le vendite della serie F sono diminuite dell'11% dopo che il suo principale fornitore di alluminio ha subito due incendi in fabbrica.
 Un modello di intelligenza artificiale cinese economico si sta avvicinando ad Anthropic e OpenAI.
Il GLM-5.2 a peso aperto di Z.ai si posiziona al quarto posto in un importante benchmark e costa molto meno di Claude o GPT-5.5, mentre le restrizioni all'esportazione negli Stati Uniti rimodellano la corsa all'IA.
Un modello di intelligenza artificiale cinese economico si sta avvicinando ad Anthropic e OpenAI.
Il GLM-5.2 a peso aperto di Z.ai si posiziona al quarto posto in un importante benchmark e costa molto meno di Claude o GPT-5.5, mentre le restrizioni all'esportazione negli Stati Uniti rimodellano la corsa all'IA.
Perché il prossimo salto nell'IA video è insegnare agli avatar a vedere e ascoltare
I modelli di avatar interattivi stanno evolvendo oltre la fedeltà verso la reattività in tempo reale. Un framework a tre livelli, dal parlare all'ascoltare fino al vedere, mappa il percorso dalla generazione unidirezionale agli agenti video conversazionali completi.