Почему следующий шаг в видео ИИ заключается в обучении аватаров видеть и слышать
TL;DRAI видео переходит от гонки за фиделити к гонке за интерактивностью. Новый класс интерактивных моделей аватаров можно оценивать по трем уровням: Уровень 1 (говорить), Уровень 2 (говорить и слушать) и Уровень 3 (говорить, слушать и видеть). Переход от Уровня 1 к Уровню 2, где аватар учится слушать и реагировать в реальном времени, является прорывом, который превращает говорящее лицо в убедительного собеседника.
В последние несколько лет прогресс в генеративном видео и ИИ-аватарах измерялся почти исключительно по фиделити, при этом каждая новая модель достигала значительного прогресса в предоставлении более четких деталей, лучшей физики и более плавного движения, упакованных в более длинные клипы. Эта гонка далеко не окончена, но начинает терять более интересное направление. Видео, как формат онлайн-медиа, эволюционирует от статического, похожего на трансляцию опыта к более интерактивному.
Программное обеспечение все чаще управляется агентами, а не кнопками и меню, и для почти любого рабочего процесса, который вы можете назвать, кто-то создает агента для его обработки. Параллельно гибридные архитектуры, которые объединяют авторегрессионные и диффузионные методы, стали одной из самых живых областей видеонаучных исследований. И растущее число команд рассматривает интерактивное видео как основу для совершенно новых классов приложений, от симуляции открытого мира до живого диалога. Соединив это вместе, вывод довольно ясен: интерактивность, а не разрешение, становится границей.
В результате появляется новая категория видеомоделей, задача которых — производить говорящего агента, который реагирует на человека в реальном времени, с задержками, достаточно низкими для поддержания естественного разговора, обычно менее одной секунды. Аналогично тому, как автомобили с автопилотом определяются шестью уровнями автоматизации, эти Интерактивные Модели Аватаров имеют три уровня интерактивности, определяемые их техническими возможностями.
💜 технологий ЕС Последние новости из технологической сцены ЕС, история от нашего мудрого основателя Бориса и немного сомнительного ИИ-искусства. Это бесплатно, каждую неделю, в вашем почтовом ящике. Подпишитесь сейчас!Система Уровня 1 может говорить. Она полностью управляется своим собственным аудио и не осознает человека перед собой. Почти каждая доступная сегодня система говорящих аватаров достигает этого уровня производительности. Это проблема односторонней генерации: данная речь, произвести правдоподобное говорящее лицо.
Система Уровня 2 может говорить и слушать. Она принимает аудио пользователя, а также свое собственное, и реагирует, пока другой человек говорит. Эти реакции включают небольшие визуальные сигналы, которые производят настоящие слушатели, такие как кивок согласия или изменение выражения лица, и голосовые сигналы, такие как короткое «м-м» для выражения признания. Это принципиально более сложная проблема, чем Уровень 1, потому что модель больше не генерирует в изоляции. Ей нужно интерпретировать входящий сигнал и непрерывно на него реагировать, в реальном времени.
Система Уровня 3 может говорить, слушать и видеть. В дополнение к аудио она принимает видеопоток с камеры пользователя, чтобы реагировать на позу, жест и выражение лица так, как люди адаптируются друг к другу во время видеозвонка.
Причина, по которой мы хотим эволюционировать за пределы моделей Уровня 1, заключается в том, что аватар, который говорит, не осознавая человека, с которым он говорит, выглядит живым, не будучи отзывчивым. Он движется, пока вы говорите, часто так, что не имеет ничего общего с тем, что вы говорите, и эффект оказывается удивительным или тревожным. В сравнении с системами разговоров только с аудио, которые, по крайней мере, остаются тихими и внимательными, пока вы говорите, не слушающий аватар иногда может казаться хуже, чем отсутствие аватара вообще.
Вот почему переход от Уровня 1 к Уровню 2 имеет наибольшее значение. Убедительное слушание аватара — это то, что превращает говорящее лицо во что-то, что ощущается как собеседник. Достигнуть этого сложнее, чем кажется, потому что слушание не является чисто визуальным. Голосовая сторона, время прерывания, просодия признания, полусекундная пауза перед реакцией несут столько же смысла вовлеченности, сколько и кивание. Наивный подход заключается в том, чтобы прикрепить разговорную голосовую систему к видеомодели в стек. Более многообещающий путь — совместное моделирование аудио и движения, изучая, как голос и движение формируют друг друга в реальном времени. Урок из недавних мультимодальных видеомоделей заключается в том, что предсказание обеих модальностей вместе часто является тем местом, где реализм пересекает порог, а не медленно продвигается вперед.
Модели аватаров Уровня 3 могут использовать видеопоток с камеры человека, чтобы создать идеальный разговорный опыт, который идеально воспроизводит видеозвонок. Например, представьте, что вы разговариваете с кем-то; если они встают и уходят, то, естественно, вы прекращаете говорить, потому что это ясный сигнал о том, что разговор завершен. Поэтому интерактивные аватары Уровня 3 не только реагируют на эмоции или тон голоса человека, но и на то, что делает пользователь. В результате они могут полностью моделировать взаимодействия между людьми.
Стремление к Уровню 3 является одной из самых амбициозных задач в прикладных видеонаучных исследованиях, и достижение этой цели потребует постоянной, накапливающейся работы в области данных, моделей и системной инженерии, в чем у Synthesia отличная репутация.
Другие статьи
 Getty отменяет слияние с Shutterstock на сумму 3,7 миллиарда долларов из-за условий в Великобритании
Getty Images прекращает слияние с Shutterstock на сумму 3,7 миллиарда долларов после того, как CMA Великобритании потребовала продажу, которую она не примет, несмотря на одобрение антимонопольных органов США.
Getty отменяет слияние с Shutterstock на сумму 3,7 миллиарда долларов из-за условий в Великобритании
Getty Images прекращает слияние с Shutterstock на сумму 3,7 миллиарда долларов после того, как CMA Великобритании потребовала продажу, которую она не примет, несмотря на одобрение антимонопольных органов США.
 Продажи Ford в США во втором квартале упали на 10,3%, так как продажи электромобилей снизились на 40,7%, а нехватка алюминия затронула грузовики серии F.
Ford продал 549,200 автомобилей во втором квартале, что на 10.3% меньше. Продажи чистых электромобилей упали на 40.7%. Продажи серии F снизились на 11% после того, как его главный поставщик алюминия пострадал от двух заводских пожаров.
Продажи Ford в США во втором квартале упали на 10,3%, так как продажи электромобилей снизились на 40,7%, а нехватка алюминия затронула грузовики серии F.
Ford продал 549,200 автомобилей во втором квартале, что на 10.3% меньше. Продажи чистых электромобилей упали на 40.7%. Продажи серии F снизились на 11% после того, как его главный поставщик алюминия пострадал от двух заводских пожаров.
 Google проигрывает последнюю апелляцию по рекордному штрафу ЕС в размере 4,1 миллиарда евро за Android
Суд Европейского Союза отклонил окончательную апелляцию Google против штрафа в размере 4,1 миллиарда евро за антимонопольные нарушения в Android, завершив восьмилетнее дело.
Google проигрывает последнюю апелляцию по рекордному штрафу ЕС в размере 4,1 миллиарда евро за Android
Суд Европейского Союза отклонил окончательную апелляцию Google против штрафа в размере 4,1 миллиарда евро за антимонопольные нарушения в Android, завершив восьмилетнее дело.
 Cloudflare дает ИИ-краулерам срок до сентября, чтобы заплатить.
С 15 сентября Cloudflare по умолчанию будет блокировать боты для обучения ИИ на страницах с рекламой и выплачивать издателям, когда их контент формирует ответ ИИ.
Cloudflare дает ИИ-краулерам срок до сентября, чтобы заплатить.
С 15 сентября Cloudflare по умолчанию будет блокировать боты для обучения ИИ на страницах с рекламой и выплачивать издателям, когда их контент формирует ответ ИИ.
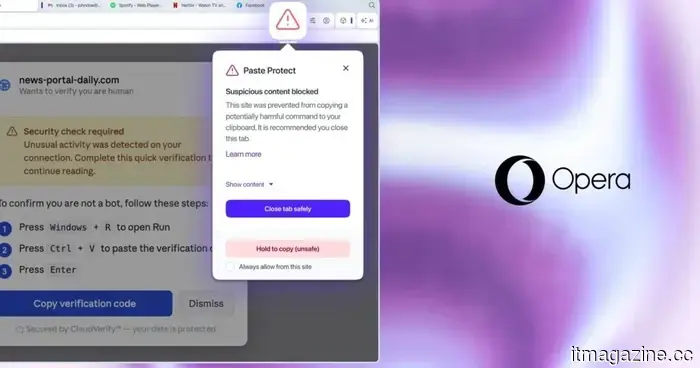 Новая функция Paste Protect в Opera предотвращает атаки через буфер обмена, которые ваш антивирус не может поймать.
Новая функция Paste Protect в браузере Opera блокирует атаки ClickFix на уровне системы, что делает его первым крупным браузером, который решает проблему, с которой антивирусное программное обеспечение не справляется.
Новая функция Paste Protect в Opera предотвращает атаки через буфер обмена, которые ваш антивирус не может поймать.
Новая функция Paste Protect в браузере Opera блокирует атаки ClickFix на уровне системы, что делает его первым крупным браузером, который решает проблему, с которой антивирусное программное обеспечение не справляется.
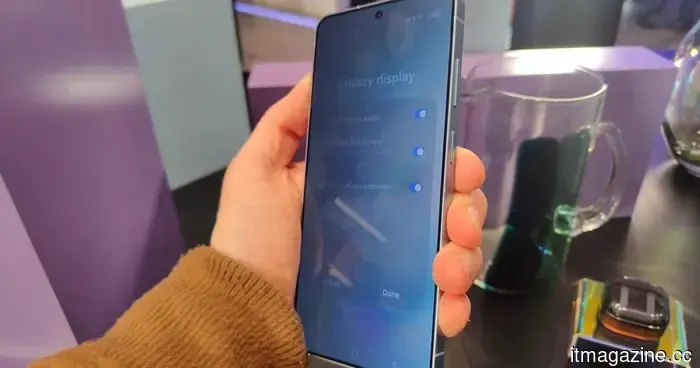 Samsung может прекратить ограничивать доступ к анти-подсматривающему дисплею Galaxy S26 Ultra с серией Galaxy S27.
Новая утечка утверждает, что Samsung может представить свою технологию дисплея Flex Magic Pixel для обеспечения конфиденциальности во всей линейке Galaxy S27, включая базовую модель, Plus, Pro и Ultra.
Samsung может прекратить ограничивать доступ к анти-подсматривающему дисплею Galaxy S26 Ultra с серией Galaxy S27.
Новая утечка утверждает, что Samsung может представить свою технологию дисплея Flex Magic Pixel для обеспечения конфиденциальности во всей линейке Galaxy S27, включая базовую модель, Plus, Pro и Ultra.
Почему следующий шаг в видео ИИ заключается в обучении аватаров видеть и слышать
Интерактивные модели аватаров развиваются от фидельности к реактивности в реальном времени. Трехуровневая структура, от разговора к слушанию и видению, прокладывает путь от односторонней генерации к полным разговорным видео-агентам.