
AWS experienced an overheating outage in northern Virginia, causing disruptions to Coinbase.
A cooling system at a single data center fell behind schedule. AWS rerouted traffic from the impacted zone and indicated that it would take longer than anticipated to fully restore the remaining services.
On Thursday, Amazon Web Services reported that one of its data centers in northern Virginia was overheating, which was affecting customer workloads. Engineers were still in the process of bringing the site back online when most users had already gone to bed.
The issue stemmed from increased temperatures in a single data center due to an inadequate cooling system, which compelled AWS to throttle and partially redirect traffic away from the impacted Availability Zone. According to the company, additional cooling resources began to come back online a few hours after the initial impact reports, and "early signs of recovery" were noted soon thereafter.
However, a subsequent update was less encouraging: it was taking longer than planned to provide enough additional cooling to safely restart the remaining systems, and AWS did not provide a timeline for full restoration.
Coinbase confirmed that its trading platform difficulties were a result of the AWS incident. After several hours of market disruptions, the exchange announced that all markets had been re-enabled and trading had returned to normal.
CME Group, the largest derivatives marketplace globally, also encountered problems with its CME Direct platform during the same period but only referred to the cause as "essential maintenance," without clarifying if the AWS incident was a contributing factor. Both companies opted not to provide additional comments outside of business hours.
The northern Virginia cluster, known as US-East-1 in AWS terminology, is the company’s oldest, busiest, and most densely populated region. An Availability Zone in this region includes one or more physical data centers that are designed to operate independently, and AWS's official guidance during recovery was standard: customers operating in the affected zone should fail over to another zone. This works efficiently for engineering teams that have prepared for this scenario; however, it is less effective for those that have not.
This pattern is beginning to appear more familiar. AWS experienced a significantly more extensive outage last October when a DNS resolution failure in DynamoDB caused ripple effects across over a hundred services, impacting platforms such as Snapchat, Reddit, United Airlines, and Coinbase. That event lasted about fourteen hours and was the largest internet-wide disruption since the CrowdStrike software fault in 2024.
Just a month later, CME faced one of its longest trading outages in years, which was traced to a cooling failure at a CyrusOne data center in the Chicago area.
The recurrence of such events is significant. Cooling failures, configuration errors, and DNS issues are different technical events, yet they consistently lead to a situation where a single physical or logical site becomes a bottleneck for a disproportionate amount of public-facing traffic. The northern Virginia region bears this burden more due to historical factors than deliberate design.
AWS established the region in 2006, and since then, US-East-1 has accumulated workloads, regulatory dependencies, and customer inertia. Although hyperscalers are investing tens of billions to expand other regions, the concentration of customers in US-East-1 is unlikely to change quickly.
Coinbase’s vulnerability to cloud issues is part of a broader narrative. The Cloudflare outage that brought down Coinbase and other exchanges in 2019 represented a different failure mode, but the same lesson applies. This is one reason why crypto exchanges have spent the intervening years planning for multi-region failover capabilities.
Thursday’s incident illustrates that even with those preparations, a single cooling failure can still disrupt a market expected to operate 24/7.
CME's situation is more complicated. Derivatives markets rely on intricate margin and clearing pipelines that do not degrade gracefully; an outage during peak Asian hours, like Thursday's, impacts clearing-cycle deadlines that facilitate money movement the following morning.
Whether the CME issue was directly linked to the AWS incident will influence how regulators view the conversation on trading resilience.
AWS has not provided an estimate of the affected workloads, and Amazon has yet to explain why the cooling system failed, whether due to equipment issues, environmental conditions, or a combination of both.
The northern Virginia region has been adapting to a surge of new AI training and inference abilities over the past year, which tend to operate at higher temperatures and density than traditional cloud workloads. Whether this factor is coincidentally relevant to Thursday’s incident or substantially contributes to its cause will be addressed in the post-incident report.
For most customers, the solution aligns with AWS's initial recommendation: to avoid running all operations in a single Availability Zone within a single region. This guidance has been part of AWS’s architecture best practices for years, and each such failure increases the costs of having overlooked it.
Other articles
 Asus’ incredibly sleek ExpertBook Ultra arrives in the US with a completely perplexing price tag.
The Asus ExpertBook Ultra features a 14-inch dual OLED display, Intel Core Ultra Series 3 performance, and enhanced security for businesses, all priced at an astonishing $3,599.99 in the US.
Asus’ incredibly sleek ExpertBook Ultra arrives in the US with a completely perplexing price tag.
The Asus ExpertBook Ultra features a 14-inch dual OLED display, Intel Core Ultra Series 3 performance, and enhanced security for businesses, all priced at an astonishing $3,599.99 in the US.
 PR and Media insights from the EU-Startups Summit 2026: what is effective and what isn’t
Founders seeking media exposure at this year's EU-Startups Summit in Valletta received a straightforward briefing from those in charge of publication decisions.
PR and Media insights from the EU-Startups Summit 2026: what is effective and what isn’t
Founders seeking media exposure at this year's EU-Startups Summit in Valletta received a straightforward briefing from those in charge of publication decisions.
 AWS experiences an overheating outage in northern Virginia, causing disruptions for Coinbase.
A shortage in the cooling system at a particular AWS data center in northern Virginia caused service interruptions on Thursday.
AWS experiences an overheating outage in northern Virginia, causing disruptions for Coinbase.
A shortage in the cooling system at a particular AWS data center in northern Virginia caused service interruptions on Thursday.
 Spotify's AI DJ now communicates in French, German, Italian, and Brazilian Portuguese.
Spotify has recently announced an expansion of its premium AI DJ feature, aimed at improving the experience for users in Europe and Brazil.
Spotify's AI DJ now communicates in French, German, Italian, and Brazilian Portuguese.
Spotify has recently announced an expansion of its premium AI DJ feature, aimed at improving the experience for users in Europe and Brazil.
 The MacBook Neo was such a tremendous success for Apple that it could soon lead to a price increase.
To increase production to 10 million units, new A18 Pro chips must be sourced from TSMC at full price instead of using binned rejects, while DRAM prices have risen by 57% and 3nm capacity has become constrained.
The MacBook Neo was such a tremendous success for Apple that it could soon lead to a price increase.
To increase production to 10 million units, new A18 Pro chips must be sourced from TSMC at full price instead of using binned rejects, while DRAM prices have risen by 57% and 3nm capacity has become constrained.
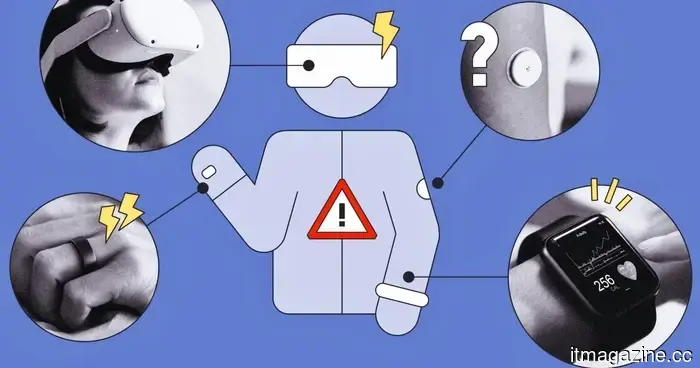 Wearables are not just a danger to privacy. Studies indicate that their hacking poses a threat described as "ransomware for the body."
Wearables are capable of more than just monitoring your steps. Recent studies caution that hackers might take advantage of them to cause physical harm, influence your emotions, or even extort you completely.
Wearables are not just a danger to privacy. Studies indicate that their hacking poses a threat described as "ransomware for the body."
Wearables are capable of more than just monitoring your steps. Recent studies caution that hackers might take advantage of them to cause physical harm, influence your emotions, or even extort you completely.
AWS experienced an overheating outage in northern Virginia, causing disruptions to Coinbase.
A failure in the cooling system at a single AWS data center in northern Virginia caused service interruptions on Thursday.