
ChatGPT, Gemini, and other AI bots often provide poor medical advice about half the time.
Individuals are increasingly using AI chatbots similarly to search engines for daily health inquiries. This trend appears more concerning following a recent study that revealed problematic responses from half of the answers across five prominent bots, even when the replies appeared well-articulated and self-assured.
Researchers assessed ChatGPT, Gemini, Grok, Meta AI, and DeepSeek using 250 prompts relating to cancer, vaccines, stem cells, nutrition, and athletic performance.
The prompts were designed to reflect frequent health concerns and common misinformation topics, measuring whether the bots adhered to scientific evidence or veered into misleading and possibly dangerous advice.
Broad inquiries revealed significant deficiencies
The most significant shortcomings arose from open-ended prompts. These broader questions yielded far more problematic responses than anticipated, while closed prompts tended to generate safer answers.
This is significant because people typically do not pose medical questions in a structured, multiple-choice format. Instead, they inquire about the effectiveness of treatments, the safety of vaccines, or ways to enhance athletic performance.
In the study, such prompts led the bots to provide answers that combined solid evidence with less reliable or misleading claims.
High confidence, poor sourcing
The issues extended beyond the answers presented. The quality of references was lacking, with an average completeness score of only 40%, and none of the chatbots managed to produce a fully accurate reference list.
This undermines one of the key reasons for trusting chatbot responses. A reply may appear well-sourced and authoritative but may not hold up once the citations are scrutinized.
The researchers also pointed out instances of fabricated references, even as the bots answered with certainty and provided minimal disclaimers.
Implications beyond a single study
While there are limitations to the findings, as the study focused on just five chatbots, these products are rapidly evolving, and the prompts were designed to challenge the models, potentially exaggerating the frequency of poor answers in normal usage.
Nonetheless, the primary takeaway is difficult to ignore. These systems were evaluated on evidence-based medical subjects, and yet half of the responses still ventured into flawed or incomplete territory.
At this point, chatbots might assist in summarizing information or shaping follow-up questions, but they currently lack the reliability needed for significant medical decision-making.


Other articles
 Wayve expands its $1.2 billion funding round with an additional $60 million from AMD, Arm, and Qualcomm.
Wayve has secured $60 million from AMD, Arm, and Qualcomm Ventures, thereby expanding its Series D funding round to $1.2 billion. Plans for robotaxi trials with Uber are set for Tokyo and London starting in 2026.
Wayve expands its $1.2 billion funding round with an additional $60 million from AMD, Arm, and Qualcomm.
Wayve has secured $60 million from AMD, Arm, and Qualcomm Ventures, thereby expanding its Series D funding round to $1.2 billion. Plans for robotaxi trials with Uber are set for Tokyo and London starting in 2026.
 Get a $75 discount on the Ray-Ban Meta smart glasses, featuring AI technology, open-ear audio, and a 12MP camera, all in a stylish frame that you'd choose to wear regardless.
Many wearable technologies require you to sacrifice your appearance for the desired features. However, the Ray-Ban Meta smart glasses do not. They are currently priced at $224.25, which is a $75 discount from their original price of $299. These glasses incorporate a 12MP ultra-wide camera, open-ear speakers, and AI assistance into a Wayfarer style frame that [...]
Get a $75 discount on the Ray-Ban Meta smart glasses, featuring AI technology, open-ear audio, and a 12MP camera, all in a stylish frame that you'd choose to wear regardless.
Many wearable technologies require you to sacrifice your appearance for the desired features. However, the Ray-Ban Meta smart glasses do not. They are currently priced at $224.25, which is a $75 discount from their original price of $299. These glasses incorporate a 12MP ultra-wide camera, open-ear speakers, and AI assistance into a Wayfarer style frame that [...]
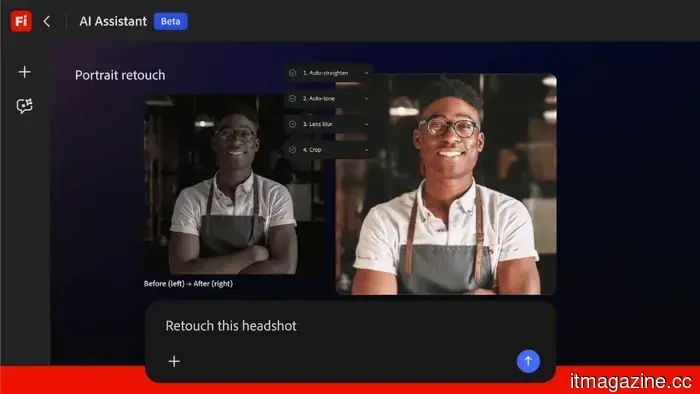 Adobe introduces the Firefly AI Assistant to manage tasks throughout Creative Cloud.
Adobe's Firefly AI Assistant employs natural language to coordinate activities across Photoshop, Premiere, Lightroom, and Illustrator. It will soon be available in public beta and includes integration with Anthropic Claude.
Adobe introduces the Firefly AI Assistant to manage tasks throughout Creative Cloud.
Adobe's Firefly AI Assistant employs natural language to coordinate activities across Photoshop, Premiere, Lightroom, and Illustrator. It will soon be available in public beta and includes integration with Anthropic Claude.
 SaaStock's founder steps down from the decade-old brand and introduces Shift AI for the era following SaaS.
Alexander Theuma is ending SaaStock after ten years and introducing Shift AI, pointing to a $2 trillion decrease in the SaaS market cap and the decline of per-seat pricing due to the influence of AI agents.
SaaStock's founder steps down from the decade-old brand and introduces Shift AI for the era following SaaS.
Alexander Theuma is ending SaaStock after ten years and introducing Shift AI, pointing to a $2 trillion decrease in the SaaS market cap and the decline of per-seat pricing due to the influence of AI agents.
 Microsoft implements new safety measures to protect users from remote desktop attacks.
Protect yourself before it's too late.
Microsoft implements new safety measures to protect users from remote desktop attacks.
Protect yourself before it's too late.
 Auctor has come out of stealth mode with $20 million in funding, led by Sequoia.
Auctor has come out of stealth mode, securing $20 million in funding led by Sequoia Capital, with the aim of improving enterprise software implementation, a sector where 50% of projects fail to meet deadlines.
Auctor has come out of stealth mode with $20 million in funding, led by Sequoia.
Auctor has come out of stealth mode, securing $20 million in funding led by Sequoia Capital, with the aim of improving enterprise software implementation, a sector where 50% of projects fail to meet deadlines.
ChatGPT, Gemini, and other AI bots often provide poor medical advice about half the time.
A study published in BMJ Open discovered that five prominent AI chatbots frequently provided inaccurate health recommendations, with open-ended inquiries leading to the poorest responses and the quality of citations deteriorating upon examination.